
迅速介绍
midScene.js是“视觉模型驱动,支持全平台的 UI 自动化 SDK” 官方文档:https://midscenejs.com/zh/introduction.html
简单点说就是,你随便说点啥,他就能自己截屏自己去执行你文本描述的自动化步骤
使用 AI 模型驱动 UI 自动化的有两个关键点:规划合理的操作路径,以及准确找到需要交互的元素。其中“元素定位”能力的强弱,会直接影响到自动化任务的成功率。
为了完成元素定位工作,UI 自动化框架一般有两种技术路线:
- 基于 DOM + 截图标注:提前提取页面的 DOM 结构,结合截图做好标注,请模型“挑选”其中的内容。
- 纯视觉:利用模型的视觉定位能力,基于截图完成所有分析工作,即模型收到的只有图片,没有 DOM,也没有标注信息。那也就是说,该框架是完完全全和传统selenium是不同的,使用此框架必须得放弃传统的DOM自动化的思路,不管是从封装还是设计模式上
优缺点
吧啦半天,直接说优缺点
优点:
1.前端改动不用再去维护Xpath,Css这种传统路径的DOM自动化,基于纯视觉更省事儿
2.书写非常方便,配置也非常简单,只需要视觉大模型+yaml就能写,不需要写啥代码
3.可以通过插件驱动自己的浏览器,免登录,用selenium写过驱动自己的浏览器的朋友应该知道,配置有多麻烦
缺点:费钱,视觉大模型要比纯文本大模型花的token更多,什么时候图像识别也能便宜点就好了
案例展示
大模型环境配置文件.env
提前准备好视觉大模型,官网推荐豆包Doubao-Seed-1.6-Vision、qwen3-vl-plus、GLM-4.6V,我综合使用下来,qwen3-vl-plus是最不墨迹的,详情可以看midScene官网评测
所以准备好qwen3-vl-plus的配置(由于写本篇文章,qwen3.5还没有出来,现在更推荐qwen3.5)
https://midscenejs.com/zh/model-common-config.html#qwen35
MIDSCENE_MODEL_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
MIDSCENE_MODEL_API_KEY="sk-a4f203cd7手动打码ba5291d846" 为什么打码,因为我充钱了
MIDSCENE_MODEL_NAME="qwen3-vl-plus"
MIDSCENE_MODEL_FAMILY="qwen3-vl"
新建.env文件,把上面配置存进去
配置文件config.yaml
环境文件同级目录新建config.yaml,写入
# Example batch execution index YAML file
# This demonstrates how to use the multi-YAML file batch execution feature
# Concurrency settings (default: 1 for sequential execution)
concurrent: 1
# Continue execution even if one file fails (default: false)
continueOnError: false
# Summary output file
summary: "./midscene_run/output/custom-summary.json"
# Global web environment configuration (applied to all files)
web:
# All individual YAML files will inherit these settings
# viewportWidth: 1280
# viewportHeight: 720
# bridgeMode: "newTabWithUrl"
# Output directory for individual files (will be combined with file-specific paths)
# Execution order using glob patterns
files:
- "yamlTest.yaml"
Yaml测试用例文件
然后就是书写步骤的环节了,这里我拿一个实际的应用场景:
1.输入xcid,然后搜索,
2.搜索完后筛选记录。
3.打开记录,找到调用日志
4.然后点击调用日志跳转,检查跳转后的页面是否正常
这里面的步骤涉及到:输入、搜索、滚动、筛选、页面跳转、文本校验(视觉校验)基本涵盖UI自动化的大部分步骤
最后新建yamlTest.yaml,输入下面内容,并把三个文件放在同级目录即可,下面是第一版本的yaml测试用例
web:
url: http://implusreport.site.fat46.qa.nt.ctripcorp.com/managesite/index/callDetailQuery?tab=CTRIP&selBUId=-1&selLanguageList=&selCallSkillGroupType=0&selSkillGroupList=&selPhoneType=-1
bridgeMode: newTabWithUrl
closeNewTabsAfterDisconnect: true
agent:
cache:
id: "my-cache-test"
strategy: "read-write"
tasks:
# - name: 登陆
# flow:
# - aiAct: 点击账号登录
# - aiAct: 在域账户名输入框里面输入"shuai_w"
# - aiAct: 在密码输入框里面输入"Phaseless1"
# - aiAct: 点击登录按钮
# - sleep: 10000
- name: 搜索xcid并校验样式和查询结果
flow:
- aiAct: 在电话标识搜索框输入 "0bb9bb91f17706371174EXCIDEND",然后点击右边的搜索(放大镜样式)按钮
- aiAct: 点击"筛选"文字右边的漏斗按钮,弹窗出现后通话方向单选项选择呼入,通话状态单选项选择接通,点击查询
- aiAssert: 检查前端页面筛选按钮右边出现"通话方向:呼入、接通状态:接通的文字"样式
- aiAct: 点击107608861452641263085,等弹窗出现后,然后点击服务详情,服务详情内容区域滚动到最底部,点击IVR流程调用右边的"调用日志"按钮
- sleep: 10000
- aiAssert: 检查新弹出的页面左上角是否有"basebiz-aigateway-api-topic.ck"文字
由于可以通过桥接模式实现免登录操作,这里面我就把登陆部分注解掉了,如果想模拟新用户可以打开,并注释掉上面的桥接模式,运行完后,可以在report目录打开
完整过程请看VCR
没有缓存执行下来非常非常慢,虽然很精确没有出错啊,这个时候我们来看看花费了多少tokens
再来看下qwen3-vl-plus价格
https://bailian.console.aliyun.com/cn-beijing/?tab=model#/model-market/detail/qwen3-vl-plus
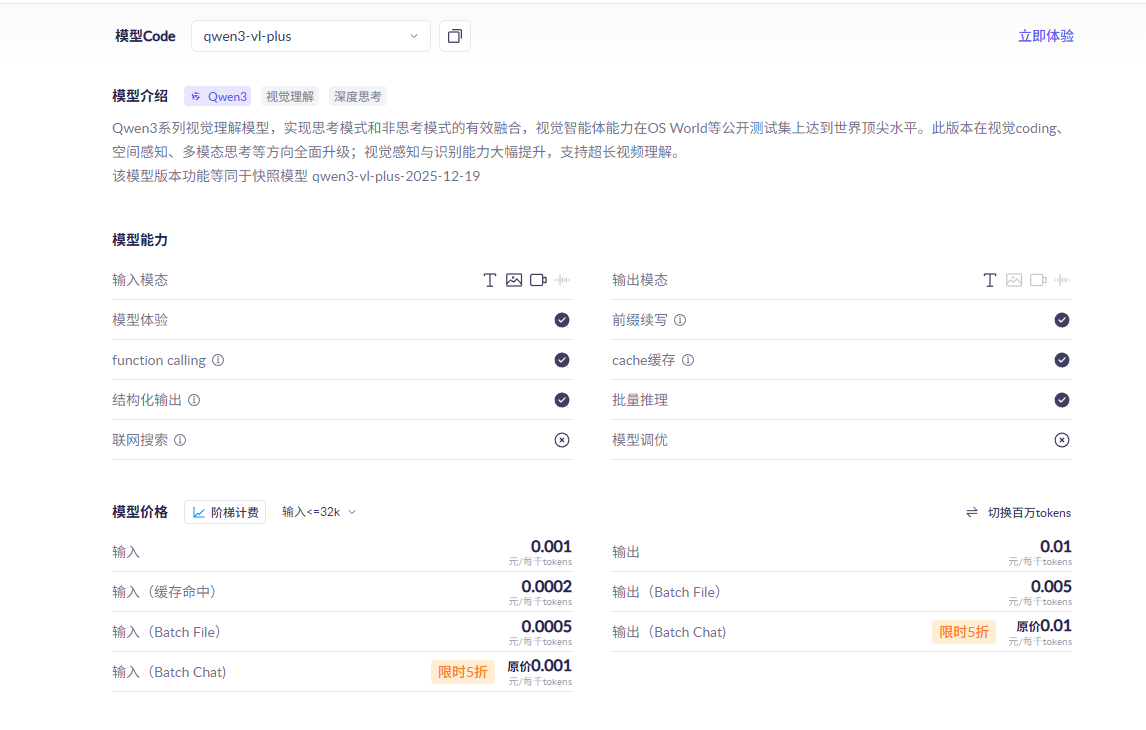
我们可以粗略估算一下这个 YAML 一次执行的费用。
输入
84419 / 1000 × 0.001
= 0.084419 元
缓存
1536 / 1000 × 0.0002
= 0.0003072 元
输出
2486 / 1000 × 0.01
= 0.02486 元
总共加一起≈ 0.11 元
好家伙,我调一次一毛钱没了,比短信还贵啊,
这我还玩个毛,所以接下来我要对token下手了
由于第一次我们缓存了,所以第二次,我们走缓存再看看花费多少
缓存midScene官方配置:https://midscenejs.com/zh/caching.html
agent:
cache:
id: "my-cache-test"
strategy: "read-write"
配置在yamlTest里面,在执行一次,请看VCR
走了缓存后可以发现,速度非常快,因为缓存部分没有调大模型,只有断言的部分调用了,当然也可以自定义缓存在哪一步需不需要调用
整体花费
输入
3933 / 1000 × 0.001
= 0.003933 元
输出
126 / 1000 × 0.01
= 0.00126 元
总计≈ 0.0052 元
一分钱都不到!!!

OK呀别着急,还有更狠的,官方由于aiAct比较废token,所以出了更精确的API,我们是可以用API来试试的,API不带缓存,API写法可参考https://midscenejs.com/zh/api.html
那根据API写法优化后的yaml测试用例为
web:
url: http://implusreport.site.fat46.qa.nt.ctripcorp.com/managesite/index/callDetailQuery?tab=CTRIP&selBUId=-1&selLanguageList=&selCallSkillGroupType=0&selSkillGroupList=&selPhoneType=-1
bridgeMode: newTabWithUrl
closeNewTabsAfterDisconnect: true
agent:
cache:
id: "my-cache-test-api"
strategy: "read-write"
tasks:
- name: 搜索 xcid 并校验样式和查询结果
flow:
# 1️⃣ 输入 xcid
- aiInput: 右侧主区域 “电话标识”右边的“ 请输入内容”输入框
value: "0bb9bb91f17706371174EXCIDEND"
- aiTap: 搜索按钮
# 2️⃣ 点击筛选
- aiTap: “筛选”文字右边的漏斗按钮
# 3️⃣ 选择筛选项
- aiTap: 通话方向选择“呼入”单选项按钮
- aiTap: 通话状态选择“接通”单选项按钮
- aiTap: 查询按钮
# 4️⃣ 断言筛选条件生效
- aiAssert: 筛选按钮右边出现“通话方向:呼入” 和 “接通状态:接通”
# 5️⃣ 点击记录
- aiTap: 列表中 ID 为 107608861452641263085 的记录
# 6️⃣ 打开服务详情
- aiTap: 服务详情按钮
# 7️⃣ 滚动到底部
- aiScroll: 服务详情内容区域
scrollType: scrollToBottom
xpath: //*[@id="main-bodyNew"]/div/div[2]/div/div/section/div/div[1]/div/div[2]/div[3]/div[2]/div/div[2]
# 8️⃣ 点击调用日志
- aiTap: ”ivr流程调用“右边的“调用日志”按钮
timeout: 10000
# 🔟 最终断言
- aiAssert: 页面出现“basebiz-aigateway-api-topic.ck”
依旧运行,midscene .\yamlTestAgent.yml
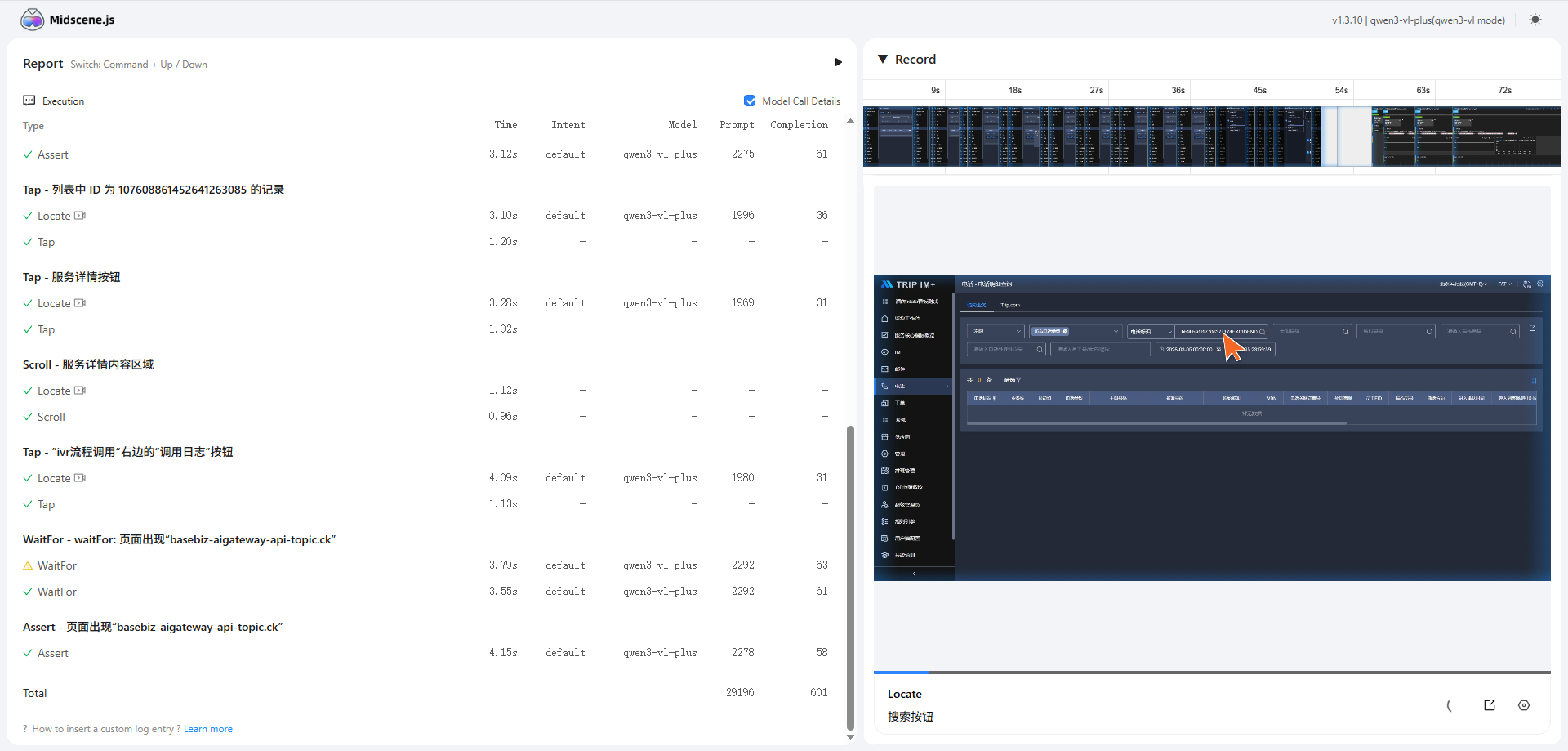
输入
29196 × 0.000001 = 0.029196
输出
601 × 0.00001 = 0.00601
总计≈ 0.035 元
3分钱!!!调教成功 
所以所以,我们可以在调试时候用midScene的api方式去调试(如果觉得上手困难,可以让AI去读midscene的api文章,然后把自己已经写好的用例润色为midScene的官方写法),并且把缓存打开,然后呢,只有断言、悬浮等待啊,或者切换页面的时候可以调一下视觉大模型,让这些复杂的操作更加精准,而对于比较常规的点击,输入,滚动等等我觉得都可以走缓存不调大模型,个人觉得对需要长期维护和小型测试项目非常有用
OK呀,又到了说再见的时候了,美好的时光总是如此短暂,马上走开,不要回来
下一篇见,即将更新Agent Skills项目实战