
本文会从Agent——>Agent组成部分——>mult-agent——>主流Agent框架——>LongGraph——>智能机票售后Mult-agent实战(基于LongGraph框架+携程实际锁单和催出票场景结合)——>如何测试Agent,需要一点点大模型基础 
一、什么是 Agent?
“Agent”在人工智能里可以理解为一个自主的智能体,它相较于大模型更具备感知、思考、决策并执行任务。
一个 Agent 通常具备以下能力:
- 感知(Perception):接收外界信息,比如用户输入。
- 决策(Reasoning):思考并判断下一步怎么做。
- 执行(Action):执行行为,比如输出内容或调用接口。
- 学习(Learning):部分高级 Agent 还能优化策略。
🧩 举个例子:
你和一个「天气小助手」聊天,问“明天北京天气”,它接收你输入(感知),决定调用天气 API(决策),获取数据后告诉你(执行)——这就是一个简单 Agent。
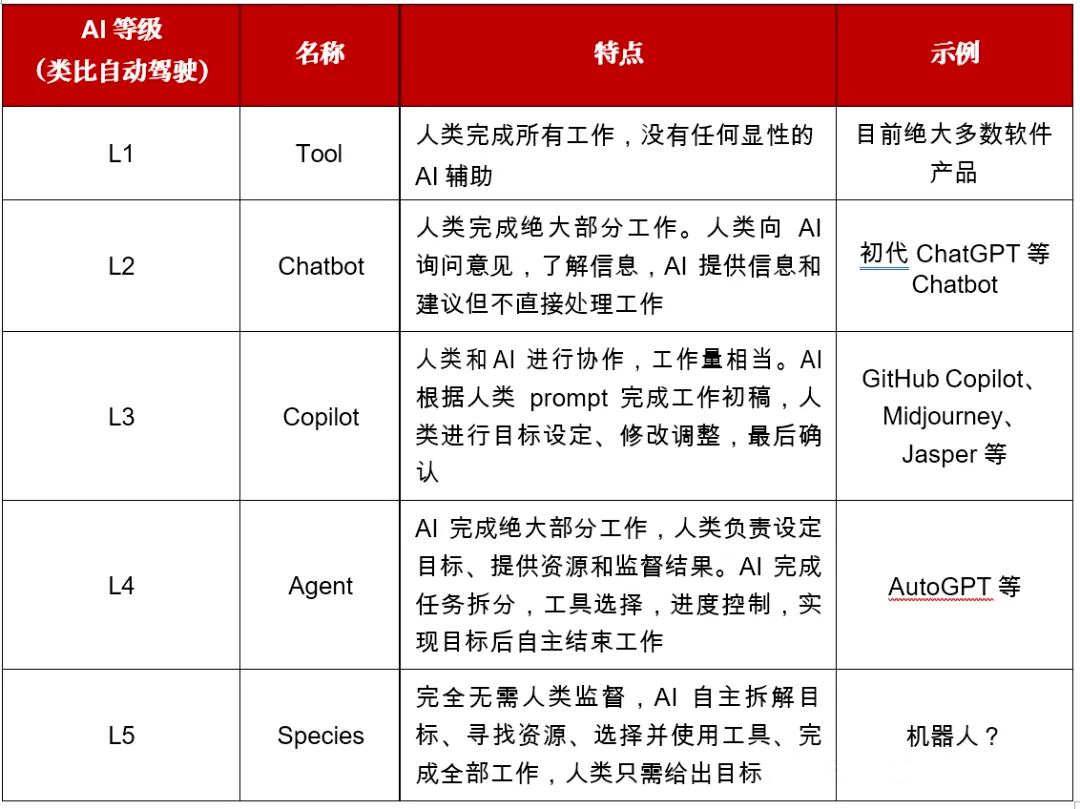
L0 ~L2级别,都是需要人类驾驶员驾驶,无论辅助驾驶功能是否介入,即使脚个在踏板上或手没有转向,需要监控辅助驾驶功能,能制动或加速以保证安全。
L3级别,人类驾驶员不驾驶,即使坐在驾驶座上,当功能请求时需要人类驾驶员接管。
L4级别,人类驾驶员不驾驶,自动驾驶功能也不需要请求驾驶员接管。
L5级别,人类驾驶员不驾驶,自动驾驶功能在任何情况下都能驾驶车辆。
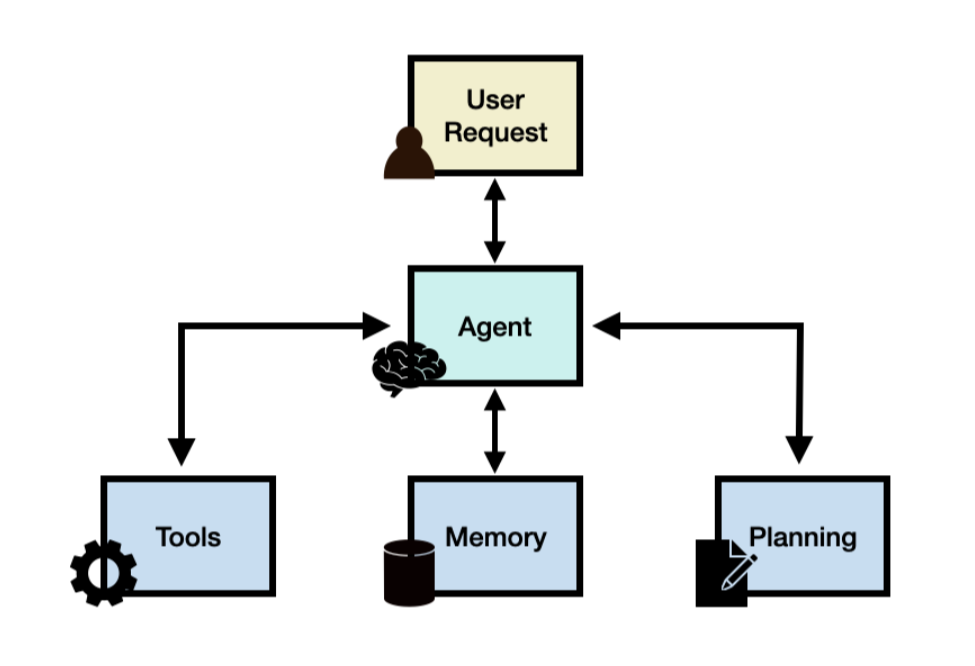
二、AI Agent的组成部分
🧠 1. 大脑(LLM - 大语言模型)
- 功能:作为Agent的推理中枢,负责理解任务、生成规划、决策行动路径。
- 关键技术:
- 思维链(Chain-of-Thought):将复杂任务拆解为子步骤(例如:用户要求“分析销售数据并生成报告” → 拆解为“查询数据库→数据清洗→趋势分析→图表生成→报告撰写”。
- 反思与优化:通过自我批评修正错误(如代码执行失败后重新调试)。
- 示例:ChatGPT作为核心大脑驱动AutoGPT,规划多步骤任务如自动编写程序。
🗃️ 2. 记忆系统(Memory)
- 短期记忆:存储当前对话上下文(受限于模型的Token窗口),用于即时推理。
- 长期记忆:通过向量数据库存储历史数据,支持快速检索(例如:用户偏好、项目历史记录)。
- 示例:医疗Agent调用长期记忆中的患者病史,结合当前症状生成诊断建议5。
📅 3. 规划能力(Planning)
将抽象目标转化为可执行步骤,包含五类方法:
- 任务分解(如MetaGPT将软件开发分为需求分析、设计、编码、测试)。
- 多计划择优:生成多个备选方案并选择最优路径。
- 外部模块辅助:调用专业工具(如调用数学库解方程)。
- 反思调整:根据执行结果动态修正计划。
- 示例:旅行规划Agent分解任务为“查天气→订机票→推荐行程”。
🛠️ 4. 工具调用(Tools)
- 功能:扩展Agent能力边界,使其能操作外部系统或获取实时数据。
- 工具类型:
- API调用(如搜索引擎、天气查询)。
- 代码解释器(执行Python脚本生成图表)。
- 硬件控制(如智能家居开关)。
- 示例:用户输入“绘制深圳气温趋势图”,Agent调用天气API获取数据,再用Code Interpreter生成图表
看不懂就对了,直接看下面的图一目了然 
三、什么是 Multi-Agent 系统?
Multi-Agent 系统是多个 Agent 的组合协作网络,每个 Agent 各司其职,像一个智能小分队。
🔁 多 Agent 系统可以:
- 拆分复杂任务,让每个 Agent 只做自己擅长的部分。
- 像流水线一样协作,提高效率。
- 通过大模型理解复杂输入、处理自然语言。
四、市面上主流的 Agent 框架
Part1:Agent 框架入门区(面向产品/前端/运营)
- Coze:零代码 AI 智能体平台 🎉🎉🎉
- Dify:低代码 LLM 应用开发平台 (垃圾,谁家卖课的讲这个趁早拉黑)
- LangFlow:可视化 LangChain工作流编辑器
Part2:进阶/研究区(面向后端/AI 工程师/科研)
- LangChain、langGraph:通用级 AI 编排框架、连续任务处理、多轮对话 🎉🎉🎉🎉🎉
- AutoGen:微软多智能体对话编排 🎉🎉🎉🎉
- CrewAI:多智能体团队+Flow 模型
- Semantic Kernel:微软企业级 Agent SDK
- Letta(MemGPT):持久记忆、多用户 Agent 环境 🎉🎉🎉
- LlamaIndex:RAG 与企业私有知识 Agent 框架
- OpenAI Agents SDK:升级版 Swarm,简约高效 🎉🎉🎉🎉
五、LangGraph 框架介绍
LangGraph 是一种“流程导向”的智能 Agent 框架,核心概念:
- 🟢 每个 Agent 是一个节点(node)
- 🔁 Agent 之间通过边(edge)连接形成状态流转
- 🌳 可以编排成状态图(StateGraph)
- 🧠 支持大模型判断条件跳转
- ✅ 兼容大模型调用与外部 API
它适合:
-
多轮对话(例如客服系统)
-
任务链式处理(例如订单流程、审批流程)
-
大模型决策节点(如模糊匹配/语言理解)
官网:https://langchain-ai.github.io/langgraph/
社区:https://www.langchain.com/join-community
得赶紧进入实战,不然一会儿就忘了 
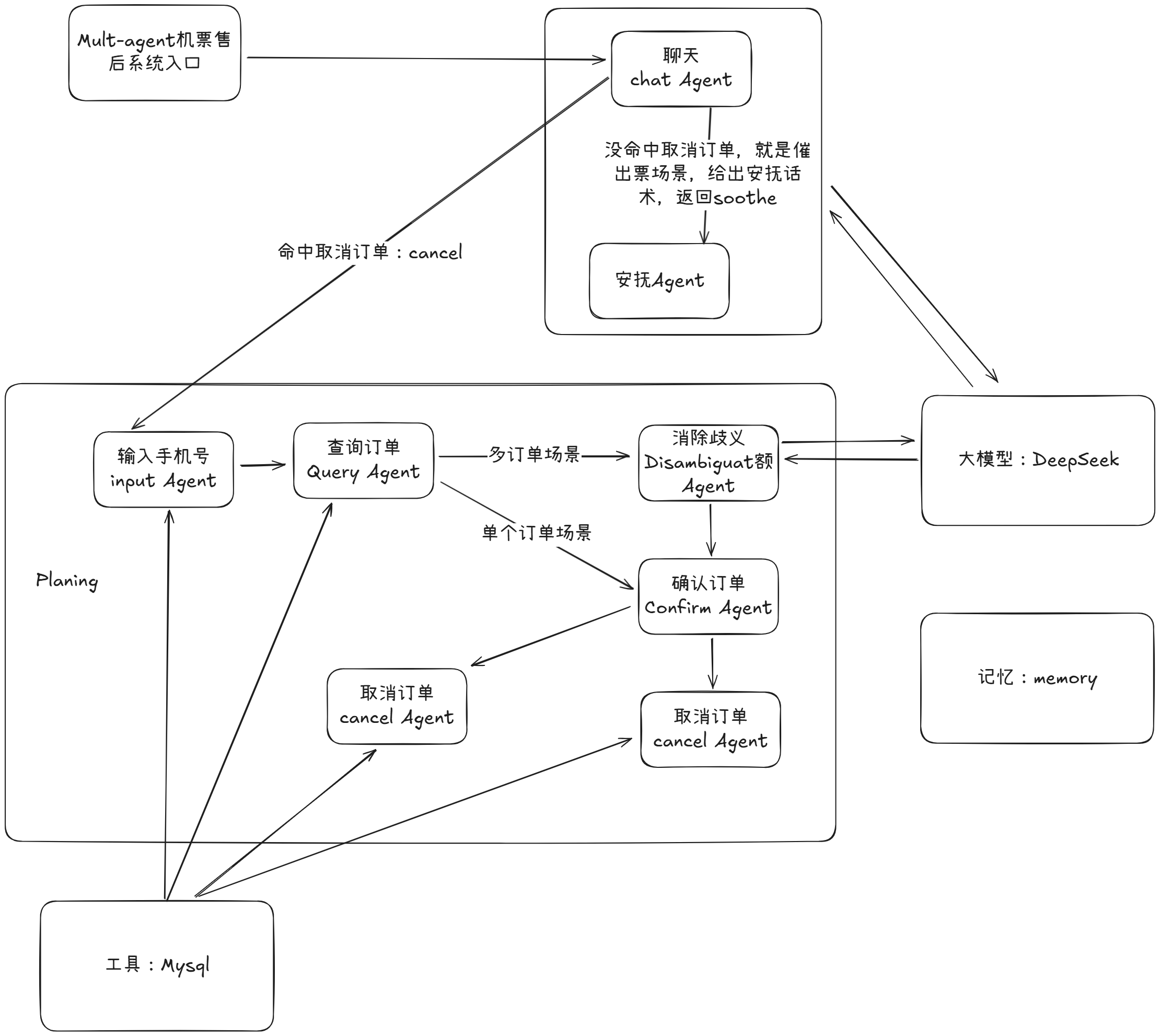
六、智能机票售后Mult-agent实战
原来的通过询问酒店日期锁单场景:prompt提示内容太多,就单一个日期锁单场景其实可以拆分成错别字Agent+方言Agent+日期核对Agent
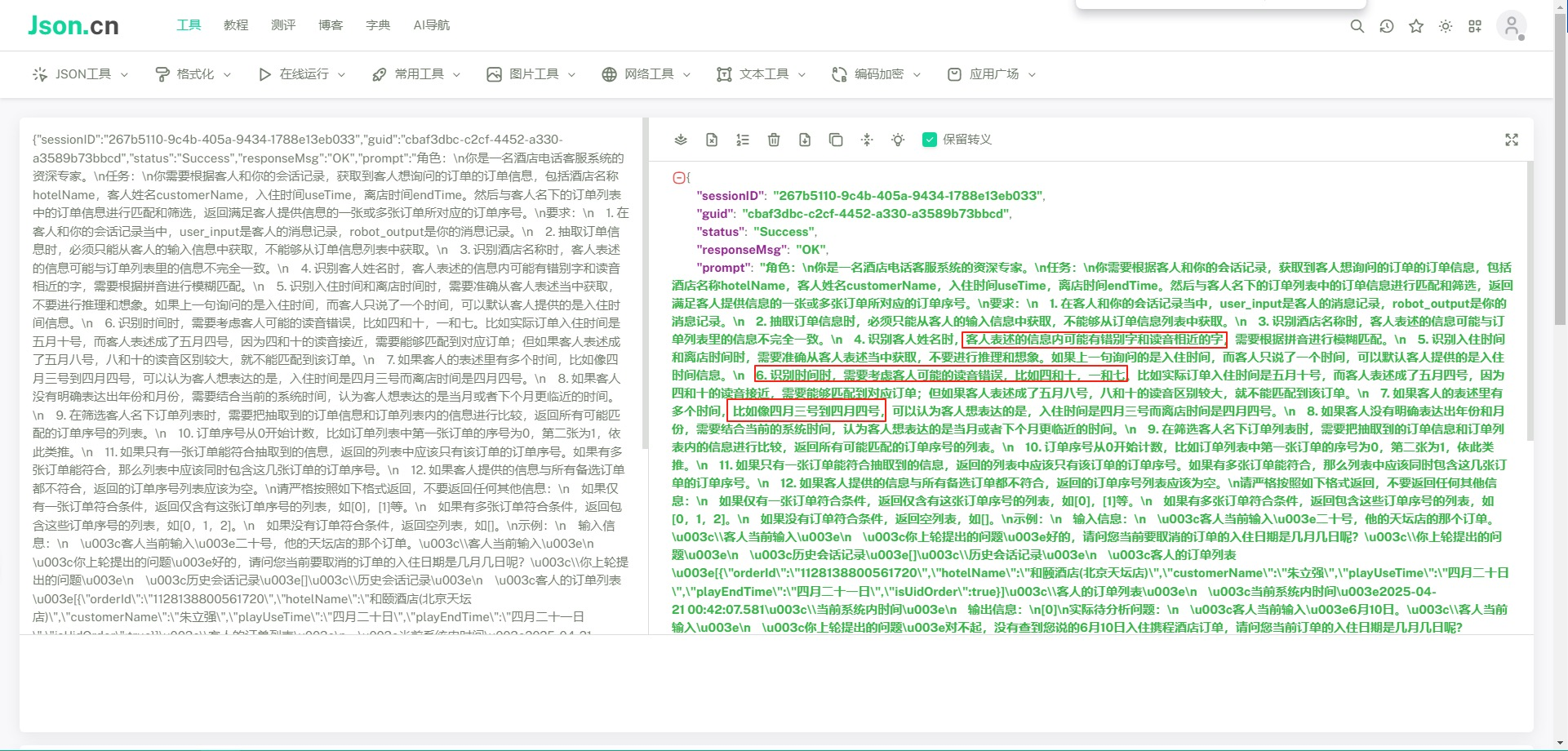
咱们项目结构图:
项目下载:https://phaseless-1302070788.cos.ap-shanghai.myqcloud.com/pythonProject/AirpotTicketAgent.7z
七:如何测试Agent or 大模型?
同行热门方案:文本向量模型+大模型辅助 
承接六,即然我们设计出来了mult-agent,顺便来测试一下大模型是否回复准确
🎯 总体介绍
这是一个用于测试 机票智能售后系统中大模型回复是否准确 的自动化测试类。它的核心目标是:
1. **确保大模型的回复不偏题**,例如用户问“什么时候出票”,大模型要“安抚+解释”而不是跑题;
2. **确保模糊取消订单话术能精准识别并锁定正确订单号**。
🧠 第一部分:文本向量模型 & 相似度判断
🔹什么是文本向量?为什么要这样做?
📘 现实问题:
计算机无法直接“理解”文字,只能处理数字。
我们想比较两个句子是不是意思相近,比如:
- 用户说:“什么时候出票?”
- 智能客服答:“订单正在出票中,请耐心等待。”
人类能理解这两个是一回事,但计算机不行。怎么办?
🔍 解决方案:将文本转换成向量(Embedding)
举例:
| 句子 | 文本向量(简化) |
|---|---|
| “什么时候出票” | [0.1, -0.3, 0.9] |
| “订单正在出票中” | [0.12, -0.31, 0.89] |
这个向量是由一个 预训练模型(如 MiniLM、BERT) 通过“压缩语言意义”方式生成的。
它的本质是让 语义相似的句子向量靠得近,语义不同的就远。
🔹 本项目使用的是哪种模型?
我们用的是 Sentence Transformers 中的:
SentenceTransformer("all-MiniLM-L6-v2")
这个模型专门用来做“句子级别”的语义理解,速度快、效果好。
🔹 如何计算相似度?
我们使用**余弦相似度(Cosine Similarity)**来比较两个句子语义是否接近:
similarity = cos(θ) = A·B / (||A|| * ||B||)
-
A·B 是点积(向量元素相乘后求和);
||A|| 是向量 A 的长度(平方和开根号);
-
当两个句子的语义方向一致时,相似度接近 1;
-
当语义完全不同时,相似度接近 0。
我们设定阈值为 0.7,表示相似度大于 0.7 就认为大模型回复“接近我们期望”。
🧑🏫 第二部分:大模型如何参与判断
🔹 向量判断只是第一层,为什么还要大模型?
因为:
- 向量模型可能忽略细节逻辑错误;
- 或者句子长短差异大时,向量相似度不稳定。
所以我们加入了 第二道保险:用大模型直接判断这句话合不合理。
🔹 具体做法:
我们设置一个明确的指令给大模型:
python复制编辑你是一个质量检查助手...
判断这段话是否合理,并属于安抚用户的出票解释。
只返回:合理 / 不合理
把大模型生成的回复当成“考试答案”交给它判分。只有两个结果:
- ✅ 合理 → 通过
- ❌ 不合理 → 报错
🔄 总结流程图(简化)
css复制编辑 用户输入(测试话术)
↓
模拟对话流程生成回复
↓
┌─────────────┴─────────────┐
↓ ↓
[向量模型判断相似度] [大模型逻辑检查]
> 0.7 ?通过 回复是否跑题?合理?
↓
✅ 全部通过
结束!累死我了,如果你看不懂,那就看不懂吧,帅老师后续会录制视频讲解,敬请期待
作业:美团京东淘宝外卖竞争激烈,帮我设计一个智能体,定时去抢三家平台的优惠券,对比最划算的优惠券然后通知我
思考:如果为了测试Agent而写更复杂的测试逻辑,甚至资源消耗也很多,那么这个还有必要测试吗???