
WEBUI自动化测试实战笔记
-
适合用户
-
- 你需要有一定的python基础
- 你要有一定的web基础
- 你要有一定的软测基础
-
软件环境(仅供参考)
软件 库/插件 Version 说明 python 3.9.6 部分库不支持3.10 pycharm 2021.2.3社区版 不需要一样,2020以后的均可 chinese(simplified) language pack/中文语言包 one dark theme plantuml integration JDK 1.8 SELENIUM GRID需要 selenium 4.3.0 建议就用这个版本,详见课前准备说明 ddddocr 1.4.1 不支持3.10及以上版本 pyyaml 6.0 pathlib 1.0.1 pytest 6.2.5 allure-pytest 2.9.45 loguru 0.6.0 pyautogui 0.9.53 pywinauto 0.6.8 Pywin32 303 pytest-base-url 1.4.2 pytest-assume 2.4.3 pytest-dependency 0.5.1 实战课 pytest-ordering 0.6 实战课 pytest-xdist 2.5.0 pytest-repeat 0.9.1 实战课 pytest-rerunfailures 10.2 实战课 -
测试环境网址
网站 URL 说明 控件测试 http://sahitest.com/demo/ 国外的一个网址用于部门SELENIUM方法测试 本地论坛 http://114.116.2.138:8090/forum.php 1-7天会使用,开源论坛 UI定位 http://121.41.14.39:8088/index.html#/ 1-7天会使用 宝利商城 http://124.223.33.41:38090/#/login 项目开始使用该环境 -
第三方网址
网站 URL 说明 selenium官网 https://www.selenium.dev/ 驱动淘宝镜像 http://npm.taobao.org/mirrors SELENIUM IDE 命令说明 https://www.seleniumhq.org/selenium-ide/docs/en/api/commands/ webdriver https://w3c.github.io/webdriver/#get-title Chrome DevTools Protocol https://chromedevtools.github.io/devtools-protocol/ selenium changelog https://github.com/SeleniumHQ/selenium/blob/trunk/py/CHANGES GITHUB下载地址(GRID下载) https://github.com/SeleniumHQ/selenium/releases/ MDN DOM API https://developer.mozilla.org/zh-CN/docs/Web/API/Document_Object_Model
一:WEBUI自动化测试实战(前言)
第一部分:自动化测试理论
-
自动化测试本质还是测试,好的测试设计非常重要(经常能看到开发做不好测试这样的话)
-
自动化测试会有编码,编码就会有bug,你的代码的健壮性如何,你的语言功底如何?
-
代码庞大了之后,总会考虑性能,软件架构,你是否有足够的算法基础,设计思维。
-
WEBUI测试偏向于功能测试,与前端联系更加紧密,你要有一定的前端基础。
-
什么样的项目适合自动化测试
-
- 软件需求变动不频繁
- 项目周期较长
- 自动化测试脚本可以重复使用
- 敏捷模式下每日构建后的测试验证
- 比较频繁的回归测试
- 软件系统界面稳定、变动较少
- 测试对象可识别、易识别
-
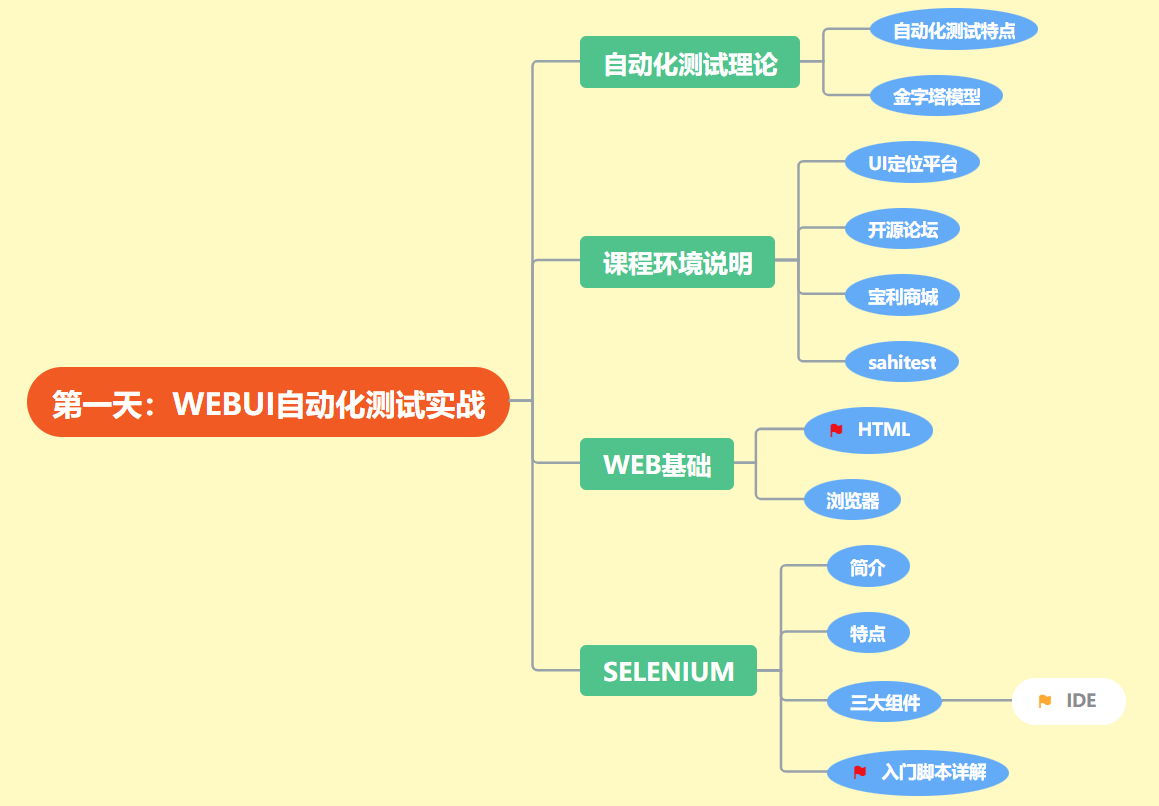
分层的金字塔模型
-
-
敏捷大师Mike Cohn在Succeeding with Agile一书中提出测试金字塔的概念。
-
我们应该有更多低级别的单元测试,而不仅仅是用户界面运行的高层的端到端的测试。
-
分层自动化测试倡导的是从黑盒UI单层到黑白盒多层的自动化测试体系,从全面黑盒的自动化测试到对系统的不同阶段、不同层次进行自动化测试。
[小型测试]是指单元测试,用于验证应用的行为,一次验证一个类。 - [中型测试]是指集成测试,用于验证模块内堆栈级别之间的互动或相关模块之间的互动。 - [大型测试]是指端到端测试,用于验证跨越了应用的多个模块的用户操作流程 - 沿着金字塔逐级向上,从小型测试到大型测试,各类测试的保真度逐级提高,但维护和调试工作所需的执行时间和工作量也逐级增加。因此,您编写的单元测试应多于集成测试,集成测试应多于端到端测试。虽然各类测试的比例可能会因应用的用例不同而异,但通常建议各类测试所占比例如下:**小型测试占 70%,中型测试占 20%,大型测试占 10%** - -
第二部分:环境说明
UI定位平台
开源论坛
| 网址 | http://114.116.2.138:8090/forum.php |
|---|---|
| 账号 | admin |
| 密码 | 123456 |
| 说明 |
自己写的网页
- 第一天写的test.html及据此剥离的min.html
第三方网站
第三部分:WEB基础
HTML基础
HTML是什么
- HTML 指的是超文本标记语言 (Hyper Text Markup Language)
- HTML 不是一种编程语言,而是一种标记语言 (markup language)
- 标记语言是一套标记标签 (markup tag)
- HTML 使用标记标签来描述网页
HTML标签(tag)是什么
- HTML 标签是由尖括号包围的关键词,比如
- HTML 标签通常是成对出现的,比如 和
- 标签对中的第一个标签是开始标签,第二个标签是结束标签
- 开始和结束标签也被称为开放标签和闭合标签
HTML元素是什么
- HTML 元素以开始标签起始
- HTML 元素以结束标签终止
- 元素的内容是开始标签与结束标签之间的内容
- 某些 HTML 元素具有空内容(empty content)
- 空元素在开始标签中进行关闭(以开始标签的结束而结束)
- 大多数 HTML 元素可拥有属性
常见的HTML标签即属性
| 标签 | 标签含义 | 属性 | 属性含义 |
|---|---|---|---|
| html | 定义 HTML 文档 | ||
| head | 定义关于文档的信息 | ||
| title | 定义文档的标题 | ||
| body | 定义文档的主体 | ||
| div | 定义文档中的节 | id | 规定元素的唯一 id。 |
| class | 规定元素的一个或多个类名(引用样式表中的类)。 | ||
| input | 定义输入控件 | type | 规定按钮的类型 |
| a | 锚,anchor,超链接 | href | 链接的目标 |
| taget | 规定在何处打开链接文档,_blank就是新开一个网页 | ||
| p | 定义段落 | ||
| button | 定义按钮 | ||
| span | 定义文档中的节 | ||
| ul | 定义无序列表 | ||
| ol | 定义有序列表 | ||
| li | 定义列表的项目 | ||
| select | 定义选择列表(下拉列表) | ||
| option | 定义选择列表中的选项 | ||
| iframe | 定义内联框架 | src | 规定在 iframe 中显示的文档的 URL |
| script | 定义客户端脚本 | src | |
| img | 定义图像 | ||
| 注释 | |||
| 文档的第一行,声明 | |||
| h1~h6 | 定义 HTML几级 标题 | ||
| br | 换行 |
CSS基础
-
Cascading Style Sheets 层叠样式表
-
是一门基于规则的语言 —— 你能定义用于你的网页中特定元素样式的一组规则
-
示例代码:我希望页面中的主标题是红色的大字
h1 { color: red; font-size: 5em; } -
格式
css选择器{ 属性1: 属性1的值; 属性2: 属性2的值; } -
你需要知道的是h1是选择器,在selenium中选择器是一种定位器,后面要重点学
-
示例html
<html lang="en"> <head> <meta charset="UTF-8"> <title>css demotitle> <style> #p2 { color: blue; font-size: 6em; } style> <link href="./cssdemo.css" rel="stylesheet"> head> <body> <p id="p1" style="color: red; font-size: 5em;">P1p> <p id="p2">P2p> <p id="p3">P3p> body> html>#p3 { color: black; font-size: 7em; } -
-
行内样式(内联样式)
内容 -
内部样式表
-
-
-
外部样式表
-
-
-
上面的HTML演示了3种CSS样式JS基础
-
-
Javascript和Java是完全不同的语言,不论是概念还是设计
-
ECMAScript标准,ECMAScript6是2015年发布的
-
API
-
- 浏览器API:DOM API和地理位置API、画布等
- 第三方API:新浪API、TwitterAPI等
URI结构

Scheme:URI的起始点,并与URI协议相关。URI schema对大小写不敏感,后面带有一个“:”。尽管在实践中可以使用未注册的schema,但URI schema应该向Internet Assigned Numbers Authority (IANA)注册。几个流行的URI schema的例子:HTTP、HTTPS、FTP和mailto。
Authority(权限):Authority字段是位于schema字段之后的第二个条目,以两个斜杠(//)开头。这个字段由多个子字段组成:
- authentication(认证信息)-可选的字段和用户名,密码,由冒号隔开,后面跟着“@”符号
- host(主机名)—注册的名称或IP地址,出现在“@”符号之后
- port(端口号)-可选字段,后面跟着一个冒号
Path(路径):Path是第三个字段,由斜杠分隔的段序列来表示,用来提供资源的位置。注意,不管authority部分存在或不存在,path都应该以一个斜杠开始,而不是双斜杠(//)。
Query(查询):Query是第四个字段,是URI的可选字段,包含一串非结构数据并以“?”和Path隔开。
Fragment(片段):Fragment是第五个组成部分,也是一个可选字段,提供指向辅助资源的方向,并以“#”开始。简单来说,Fragment字段可以用于指向HTML页面的特定元素(主资源)。
浏览器及开发者工具
快捷键
| 快捷键 | 作用 |
|---|---|
| CTRL+SHIFT+I | 打开开发者工具 |
| F12 | 打开开发者工具 |
| 右键->检查 | 打开Elements面板并直接定位到对应元素 |
| CTRL+SHIFT+C | 点击箭头开始检测元素 |
| CTRL+SHIFT+P | 打开命令输入框 |
| SHIFT+? | 打开设置界面 |
| ALT+R | 重载devtool |
| CTRL+` | 打开控制台 |
| CTRL+F5 | 去缓存刷新 |
- 在自动化测试打开的网页中用右键->检查会失效
地址栏
- chrome://version/
- chrome://about/
- chrome://inspect #appium会用到
操作技巧(以chrome为例)
★★★技巧一:元素定位
- 打开开发者工具
- 切换到element(元素面板)
- 点击左上角的箭头使其变成蓝色
- 在网页上点击你要定位的元素
- 在元素面板中会自动跳转到该元素所在的HTML代码处
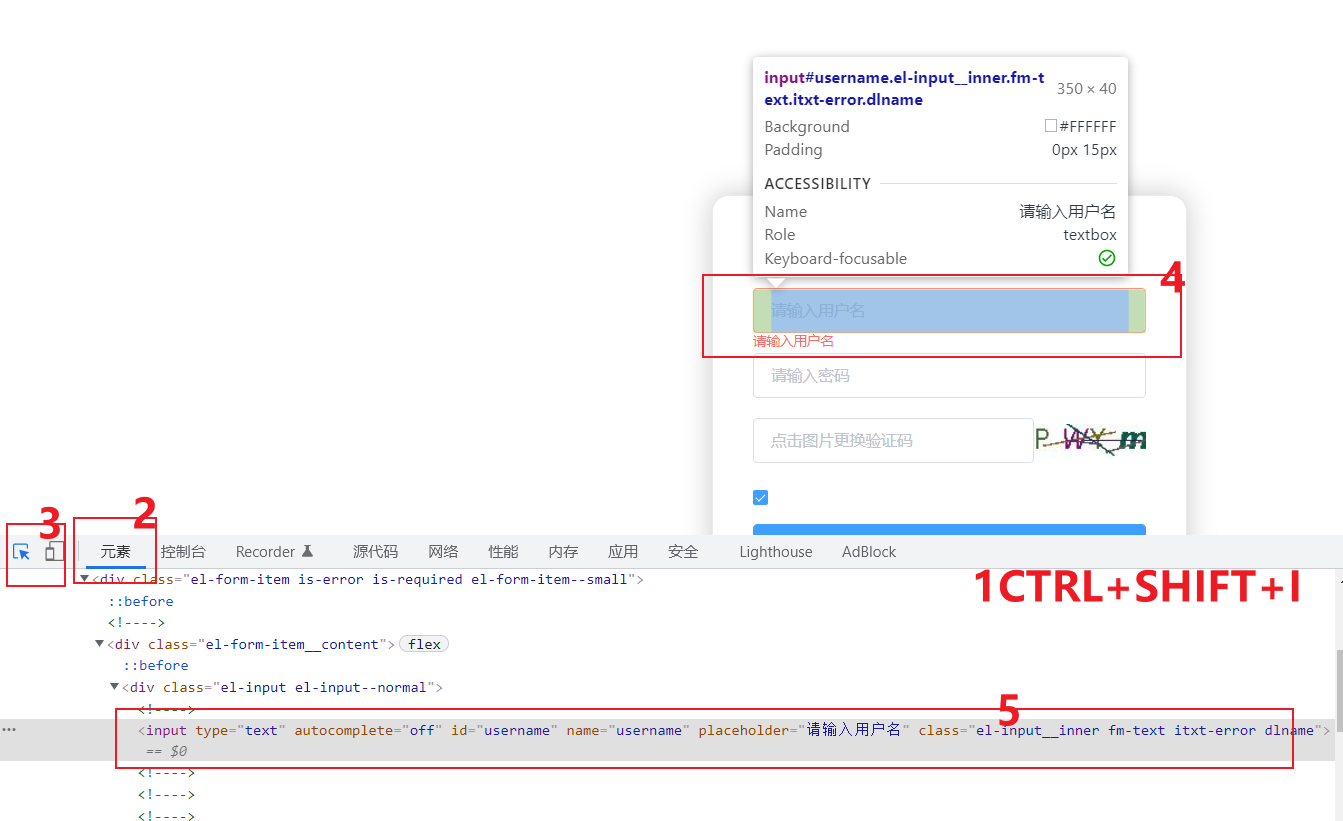
★★★★技巧二:用语法定位元素
- 打开开发者工具
- 在elements(元素)面板任意选择一个区域(或元素)点击下
- 按CTRL+F,弹出搜索框
- 在搜索框中输入XPATH表达式/CSS表达式/字符串
- 凡是符合该表达式的元素会被检索到(泛黄显示),右侧会显示1 of N,如果是1of1就是唯一定位到了,如果是1of2表示2个被定位到了,按回车会自动定位到第二个匹配的元素上,依次类推,如果在selenium中用find_element定位方法,那操作的就是第一个元素。一般情况下我们要缩小范围使得能唯一定位到,特殊场景下可以定位到多个(如爬虫),具体情况具体分析。
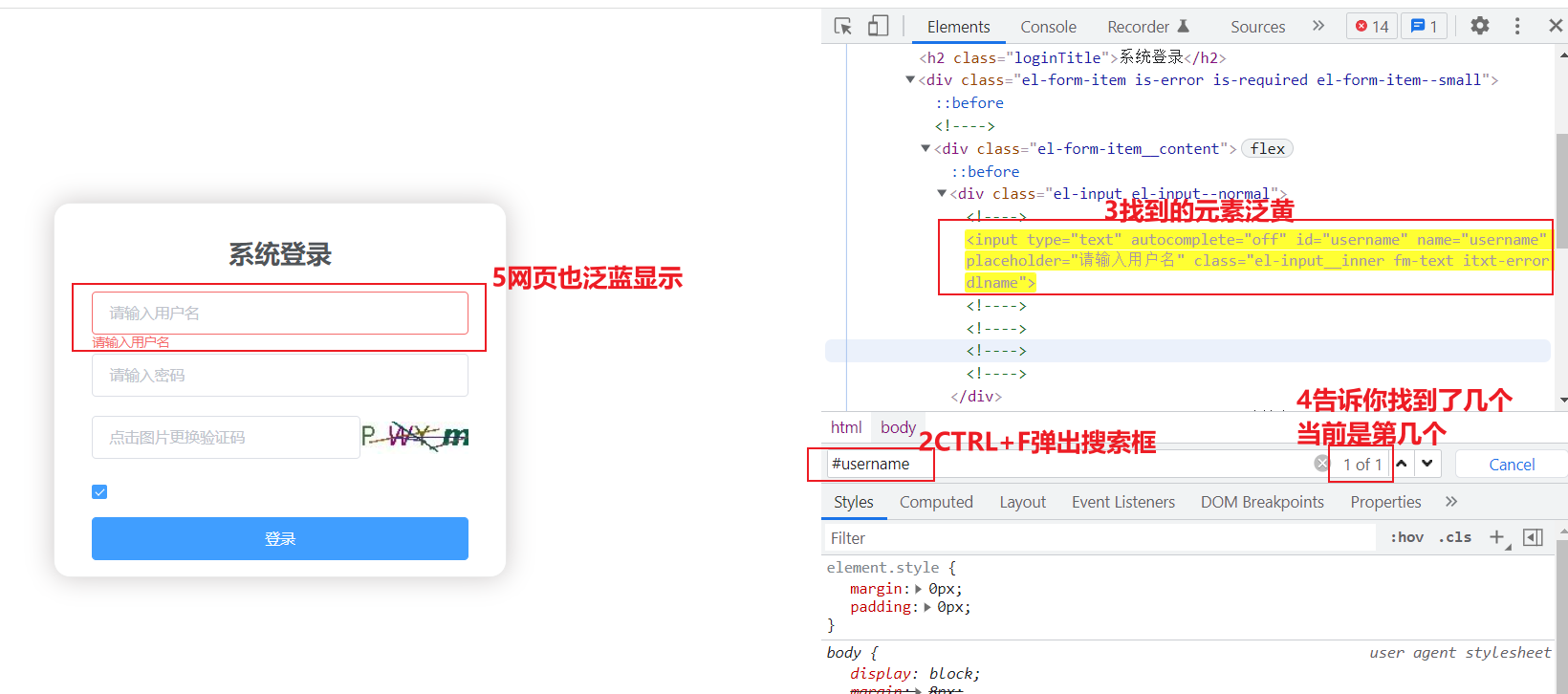
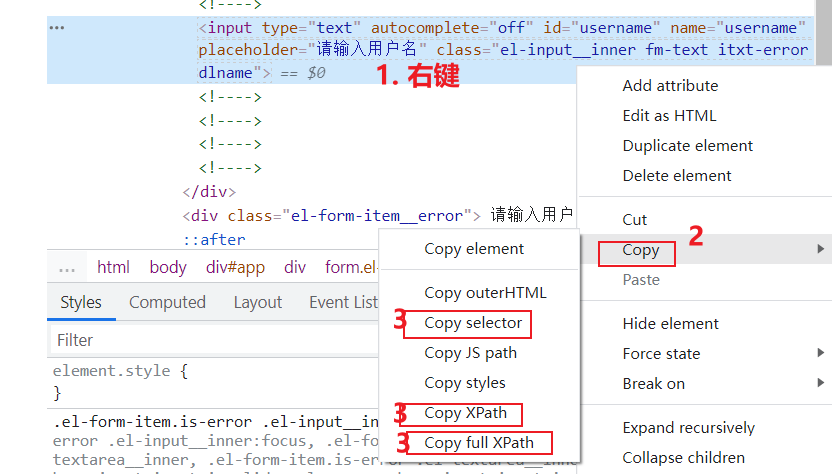
技巧三:元素操作
- 双击HTML元素的属性值可以复制其值(规避一些看不清的内容,如l和1,如0oO等)
- 右键元素,选择copy->copy selector|copy xpath|copy full xpath都可以复制该元素的表达式,但要注意有时候会失效,有时候不太可用
其他技巧
-
firefox对css支持的尤其好,提供了自动补齐功能
-
-
在console中执行setTimeout(function(){debugger},1000)可以在1s后冻结窗口,有的时候元素无法定位到就可以通过它来定位
#也可以是 setTimeout(() => {debugger;}, 4000); -
开发者工具中按shift+?打开settings界面,debugger处有个disable js的功能,有的网页无法复制是通过js实现就可以去掉。
-
在开发者工具界面按ctrl+shift +p,可以输入cdp相关命令,如全屏截图capture full size screenshot
-
常见的辅助定位的插件:selectorhub、xpath finder、xpath helper等
-
选取界面元素的时候,浏览器提供了元素的默认定位语法就是css的
-
第四部分:SELENIUM简介
-
简介
-
- 2021.11.22 RELEASE 4.1.0
- 核心理念:Selenium automates browsers
- Primarily it is for automating web applications for testing purposes, but is certainly not limited to just that.
- Boring web-based administration tasks can (and should) also be automated as well.
-
特点
-
- 开源、免费
- 多浏览器支持:Firefox Chrome IE Opera Edge Safari
- 多平台支持:Linux Windows MAC
- 多语言支持:Java Python Ruby C# JavaScript C++
- WEBUI自动化测试事实上的标准
- 简单(API)、灵活(开发语言驱动)
- 支持分布式执行测试用例
IDE
- 火狐的插件中已经无法找到SELENIUM IDE(弃用了),你可以用katalon ide替代,而chrome的插件中尚支持SELENIUM IDE,但你需要翻墙方可访问,或者使用老师提供的压缩包。
- 第一步:创建项目
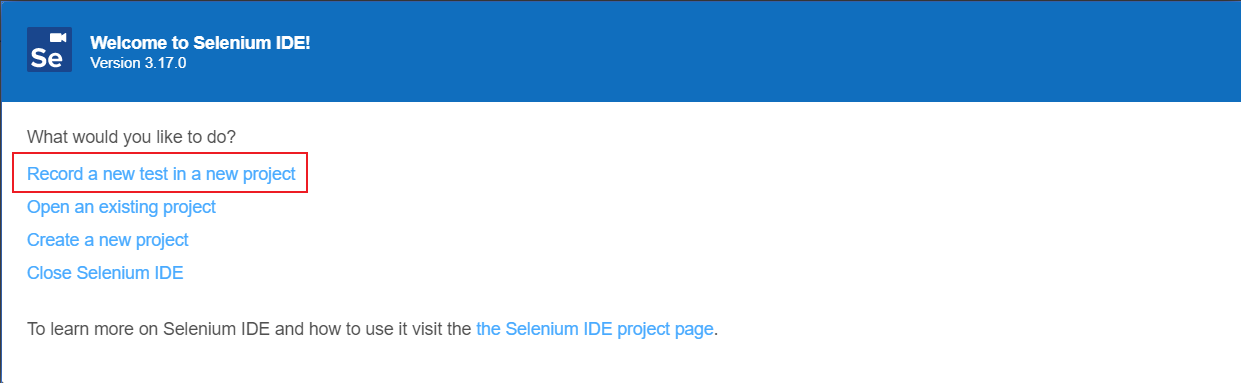
- 第二步:项目名
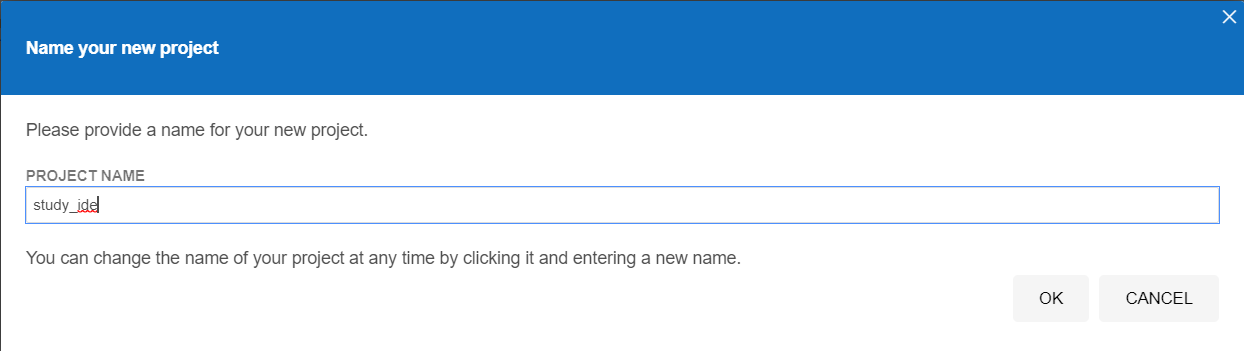
- 第三步:输入被测网址
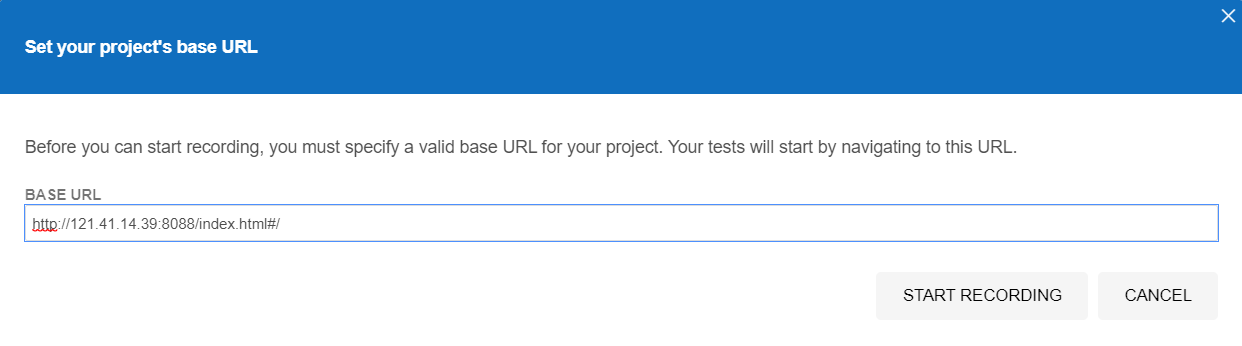
- 第四步:录制(操作网页)
- 第五步:根据需要裁剪裁剪
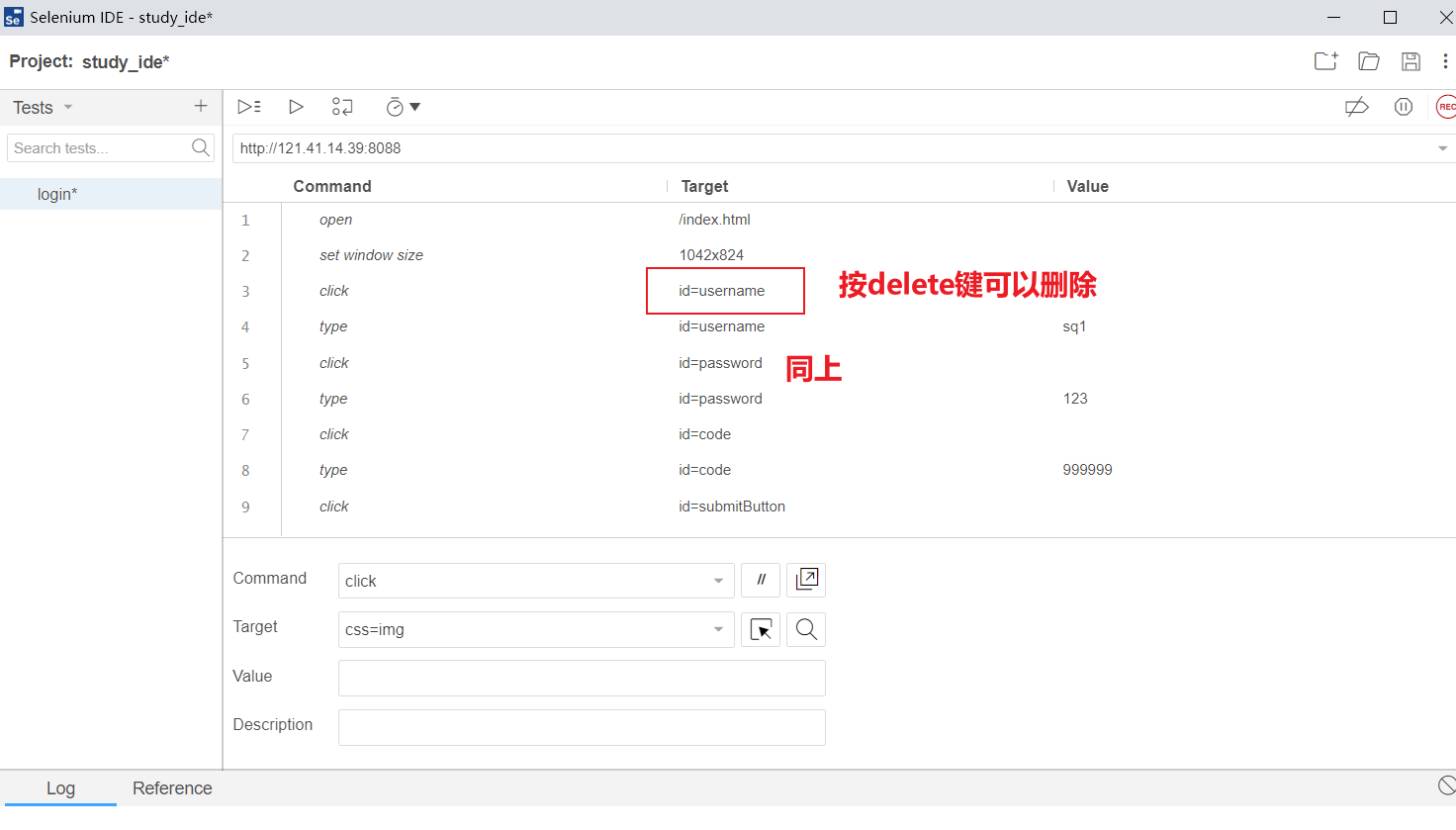
- 第六步:回放
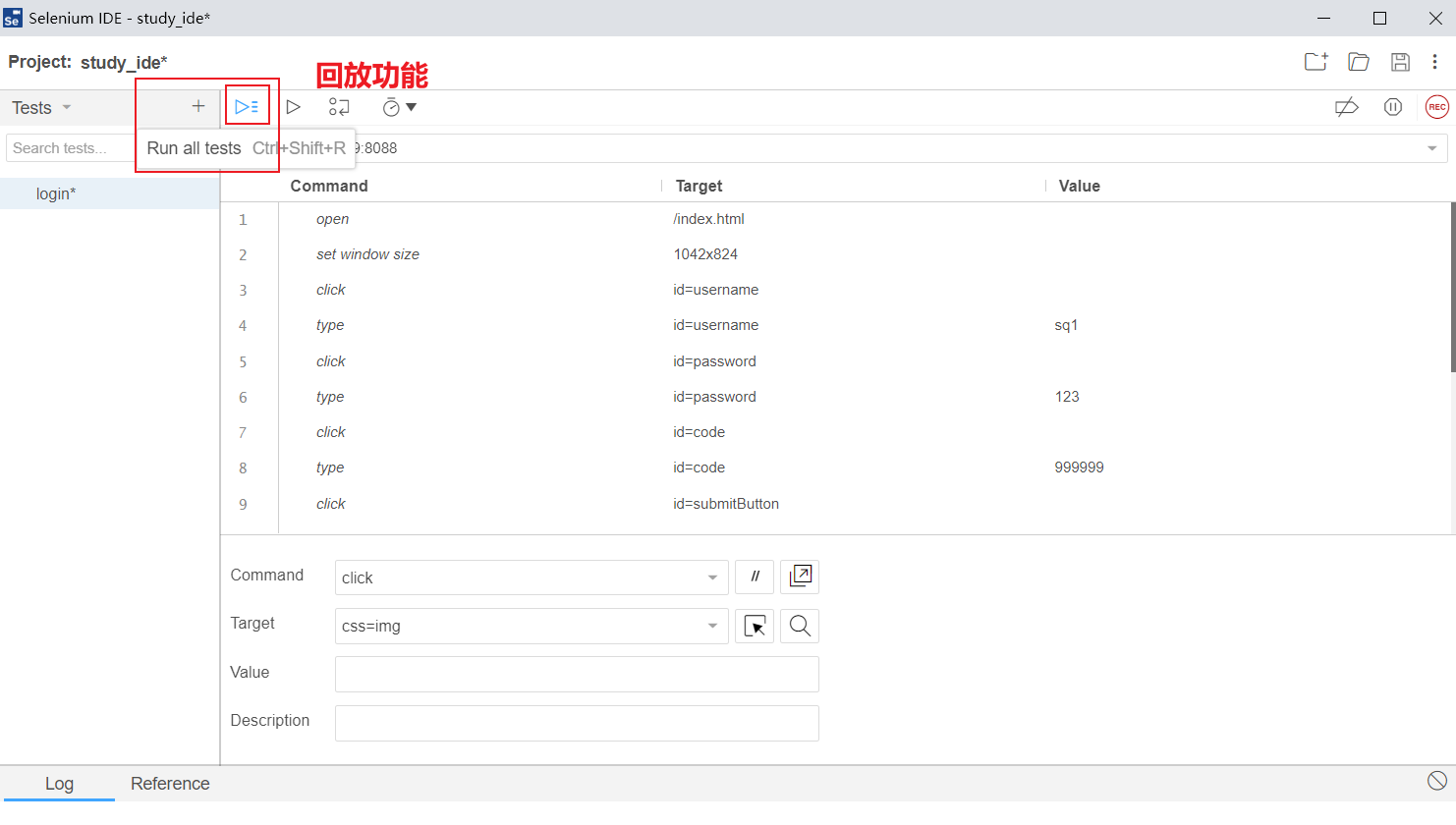
回访的时候注意有的时候网页会有记录,要保证你的步骤是闭环的(比如登录后退出),但纯写代码则不会发生这样的问题。
有的时候回访会卡住,常见open方法在set window size之前就多发,可以调换2个步骤的位置
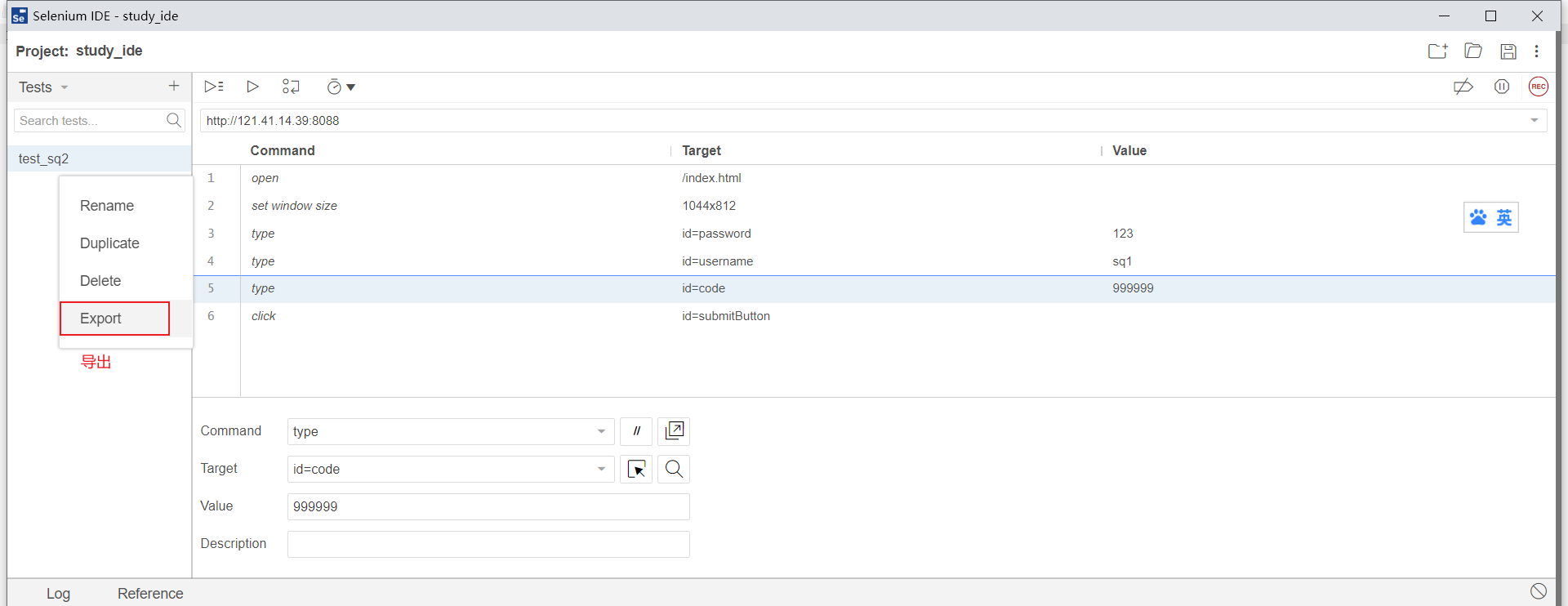
- 第七步:导出为脚本
-
注意:selenium ide的命令比较多,详见官方
入门代码详解
三行入门代码
from selenium import webdriver
driver = webdriver.Chrome() driver.get('https://www.baidu.com')
更换导入方式
from selenium.webdriver.chrome.webdriver import WebDriver
driver = WebDriver()
打开本地HTML
一、利用os模块打开
import os
from selenium import webdriver
driver = webdriver.Chrome()
html = os.path.abspath('./min.html')
driver.get(html)
二、利用pathlib库打开
from selenium import webdriver
from pathlib import Path
driver = webdriver.Chrome()
html = str(Path('min.html').resolve())
driver.get(html)
三、利用绝对路径打开
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(r'min.html的绝对路径') #在pycharm中右键复制路径/引用,选择绝对路径即可
- 注意苹果系统打开的时候需要在前面加file:///(windows也支持)
优雅的打开网页
from selenium import webdriver
with webdriver.Chrome() as driver:
driver.get('https://www.baidu.com')
认识Selenium原理
from selenium import webdriver
from time import sleep
with webdriver.Chrome(service_args=['--verbose'],
service_log_path='seleniun.log') as driver:
driver.get('https://www.baidu.com')
driver.find_element('id','kw').send_keys('松勤')
sleep(5)
-
原理
1. 对于每一个Selenium脚本,一个http请求会被创建并且发送给浏览器的驱动(CHROMEDRIVER.EXE) 2. 浏览器驱动中包含了一个HTTP Server,用来接收这些http请求 3. HTTP Server接收到请求后根据请求来具体操控对应的浏览器 4. 浏览器执行具体的测试步骤 5. 浏览器将步骤执行结果返回给HTTP Server 6. HTTP Server又将结果返回给Selenium的脚本,如果是错误的http代码我们就会在控制台看到对应的报错信息 HTTP协议是一个浏览器和Web服务器之间通信的标准协议,而几乎每一种编程语言都提供了丰富的http libraries,这样就可以方便的处理客户端Client和服务器Server之间的请求request及响应response,WebDriver的结构中就是典型的C/S结构,WebDriver API相当于是客户端,而小小的浏览器驱动才是服务器端。 那为什么同一个浏览器驱动即可以处理Java语言的脚本,也可以处理Python语言的脚本呢? 这就要提到WebDriver基于的协议:JSON Wire protocol。Client和Server之间,只要是基于JSON Wire Protocol来传递数据,就与具体的脚本语言无关了,这样同一个浏览器的驱动就即可以处理Java语言的脚本,也可以处理Python语言的脚本了。 -
代码->驱动->浏览器的关系好比乘客->司机->出租车
-
通信方式
-
-
本机:WebDriver 通过驱动程序向浏览器传递命令, 然后通过相同的路径接收信息
-
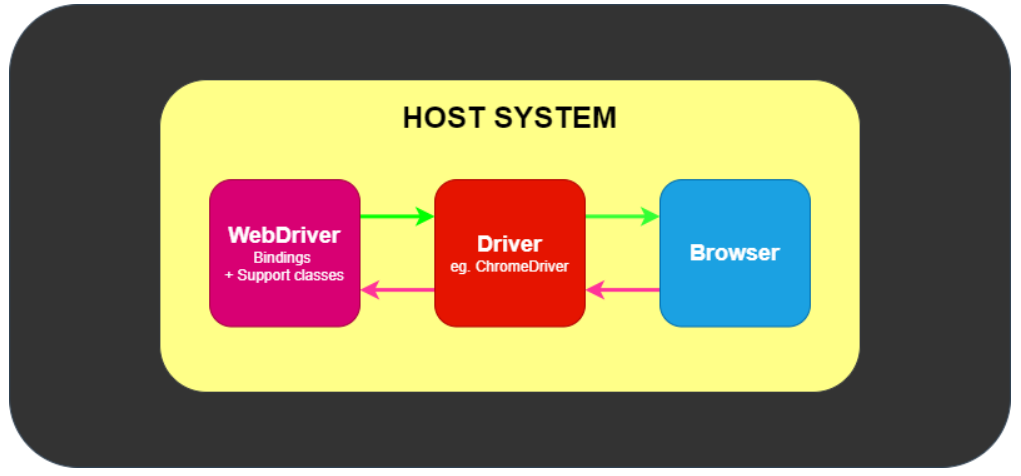
-
远程:与浏览器的通信也可以是通过 Selenium 服务器或 RemoteWebDriver 进行的 远程通信。RemoteWebDriver 与驱动程序和浏览器运行在同一个系统上。
-
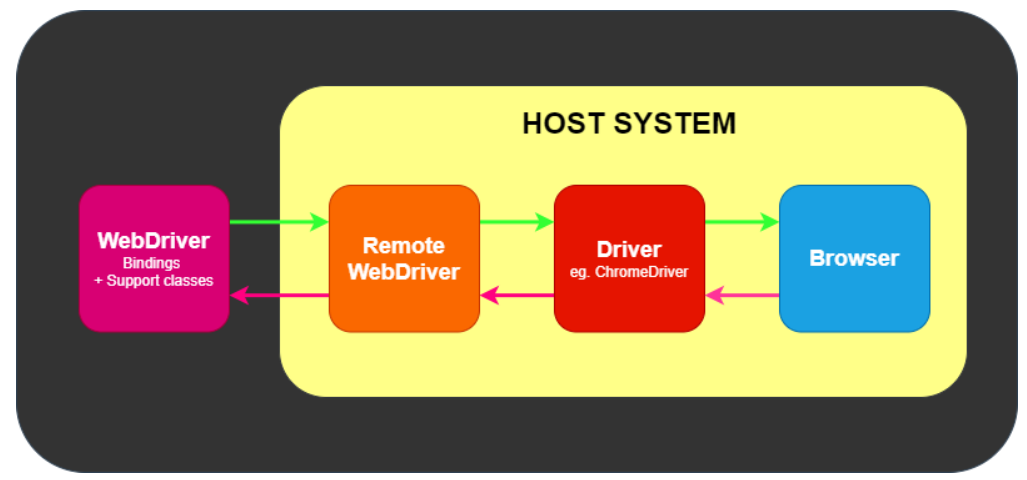
-
grid:使用 Selenium Server 或 Selenium Grid 进行,这两者依次与主机系统上的驱动程序进行通信
-

-
示例HTML
<html lang="en">
<head>
<meta charset="UTF-8">
<title>我的第一个HTMLtitle>
<style type="text/css">
li{
color: red;
// 表示所有的li标签都是这个颜色
}
style>
<link href="test1.css" rel="stylesheet"/>
head>
<body>
<h1>一级标题h1>
<div id="div1">
用户名: <input type="text" name="username" id="username" placeholder="用户名" />
<br>
密码: <input type="text" name="password" id="password" placeholder="密码" />
<br>
验证码:
<br>
<button type="button">
<span>登录span>
button>
div>
<div id="div2">
<p style="color: yellow;">这是一个段落p>
<a href="https://www.baidu.com">百度一下,你就不知道a>
<a href="https://cn.bing.com" target="_blank">有求必应a>
div>
<div id="div3">
<input type="button" id="alert" value='alert' onclick="alert('helloalert')" />
<input type="button" id="confirm" value='confirm' onclick="confirm('helloconfirm')" />
<input type="button" id="prompt" value='prompt' onclick="prompt('helloprompt')" />
div>
<div id="div4">
<ul>
<li>1li>
<li>2li>
<li>3li>
ul>
<ol>
<li>呵呵li>
<li>哈哈li>
<li>嘿嘿li>
ol>
div>
<div id="div5">
<select multiple="multiple">
<option value="1">10K-13Koption>
<option value="2">13K-16Koption>
<option value="3">16K-19Koption>
<option value="3">19K-25Koption>
select>
div>
<iframe id='if' name='nf' width="800" height="600" src="http://127.0.0.1/upload/forum.php">iframe>
body>
html>
SELENIUM:第二天:基础定位、Xpath(基础)
吴老师
二:基础定位、Xpath(基础)
第一部分:selenium 核心技术概览
-
下面的代码可以输出对象的方法,并生成md表格
from selenium import webdriver print('webdriver的对象类型是',type(webdriver)) driver = webdriver.Chrome() print('driver的对象类型',type(driver)) driver.get('https://www.baidu.com') ele_search = driver.find_element('id','kw') print('html元素的对象类型是',type(ele_search)) print('|对象属性(方法或类)|说明|') print('| ---- | ---- |') for _ in dir(ele_search): if _[0]!='_': print(f'|{_}||')
webdriver模块所有类
| 类 | 说明 |
|---|---|
| ActionChains | 动作链 |
| Chrome | Chrome类 |
| ChromeOptions | Chrome选项类 |
| ChromiumEdge | |
| DesiredCapabilities | |
| Edge | |
| EdgeOptions | |
| Firefox | 火狐类 |
| FirefoxOptions | 火狐选项类 |
| FirefoxProfile | |
| Ie | |
| IeOptions | |
| Keys | 按键 |
| Opera | |
| Proxy | |
| Remote | 远程,grid和app中用到 |
| Safari | |
| TouchActions | 触摸事件 |
| WPEWebKit | |
| WPEWebKitOptions | |
| WebKitGTK | |
| WebKitGTKOptions | |
| chrome | |
| chromium | |
| common | |
| edge | |
| firefox | |
| ie | |
| opera | |
| remote | |
| safari | |
| support | |
| webkitgtk | |
| wpewebkit |
WebDriver对象所有属性、方法
- 注意,chrome和firefox会有细微的不同
| 对象属性、方法 | 说明 |
|---|---|
| add_cookie | 添加cookie |
| application_cache | |
| back | 返回 |
| bidi_connection | |
| capabilities | |
| caps | |
| close | 关闭不退出进程 |
| command_executor | |
| create_options | |
| create_web_element | |
| current_url | 当前URL |
| current_window_handle | 当前窗口句柄 |
| delete_all_cookies | 删除所有cookie |
| delete_cookie | 删除指定cookie |
| delete_network_conditions | |
| desired_capabilities | 能力值 |
| error_handler | |
| execute | |
| execute_async_script | |
| execute_cdp_cmd | 执行cdp命令 |
| execute_script | 执行js代码 |
| file_detector | |
| file_detector_context | |
| find_element | 通用元素定位方法,找一个元素 |
| find_element_by_class_name | 通过class属性值定位,4.0废弃,4.3中移除,下同 |
| find_element_by_css_selector | 通过css选择器定位,4.0废弃 |
| find_element_by_id | 通过id属性值定位,4.0废弃 |
| find_element_by_link_text | 通过超链接文本定位,4.0废弃 |
| find_element_by_name | 通过name属性值定位,4.0废弃 |
| find_element_by_partial_link_text | 通过部分超链接文本定位,4.0废弃 |
| find_element_by_tag_name | 通过标签名定位,4.0废弃 |
| find_element_by_xpath | 通过xpath定位,4.0废弃 |
| find_elements | 通用元素定位方法,找多个元素,返回列表 |
| find_elements_by_class_name | 同上,找多个元素,返回列表 |
| find_elements_by_css_selector | 同上,找多个元素,返回列表 |
| find_elements_by_id | 同上,找多个元素,返回列表 |
| find_elements_by_link_text | 同上,找多个元素,返回列表 |
| find_elements_by_name | 同上,找多个元素,返回列表 |
| find_elements_by_partial_link_text | 同上,找多个元素,返回列表 |
| find_elements_by_tag_name | 同上,找多个元素,返回列表 |
| find_elements_by_xpath | 同上,找多个元素,返回列表 |
| forward | 前进 |
| fullscreen_window | 全屏 |
| get | 打开网址 |
| get_cookie | 获取cookie |
| get_cookies | 获取所有cookie |
| get_issue_message | |
| get_log | |
| get_network_conditions | |
| get_pinned_scripts | |
| get_screenshot_as_base64 | |
| get_screenshot_as_file | |
| get_screenshot_as_png | |
| get_sinks | |
| get_window_position | 获取窗口位置 |
| get_window_rect | 获取窗口矩形 |
| get_window_size | 获取窗口大小 |
| implicitly_wait | 隐式等待 |
| launch_app | |
| log_types | |
| maximize_window | 最大化窗口 |
| minimize_window | 最小化窗口 |
| mobile | |
| name | 浏览器名字 |
| orientation | |
| page_source | 页面源码 |
| pin_script | |
| pinned_scripts | |
| port | |
| print_page | |
| quit | 退出浏览器进程 |
| refresh | 刷新 |
| save_screenshot | 保存截图 |
| service | |
| session_id | |
| set_network_conditions | |
| set_page_load_timeout | 设置页面加载超时时间 |
| set_permissions | |
| set_script_timeout | |
| set_sink_to_use | |
| set_window_position | 设置窗口位置 |
| set_window_rect | 设置窗口矩形 |
| set_window_size | 设置窗口大小 |
| start_client | |
| start_session | |
| start_tab_mirroring | |
| stop_casting | |
| stop_client | |
| switch_to | 切换到 |
| timeouts | |
| title | 浏览器标题 |
| unpin | |
| vendor_prefix | |
| window_handles | 窗口句柄 |
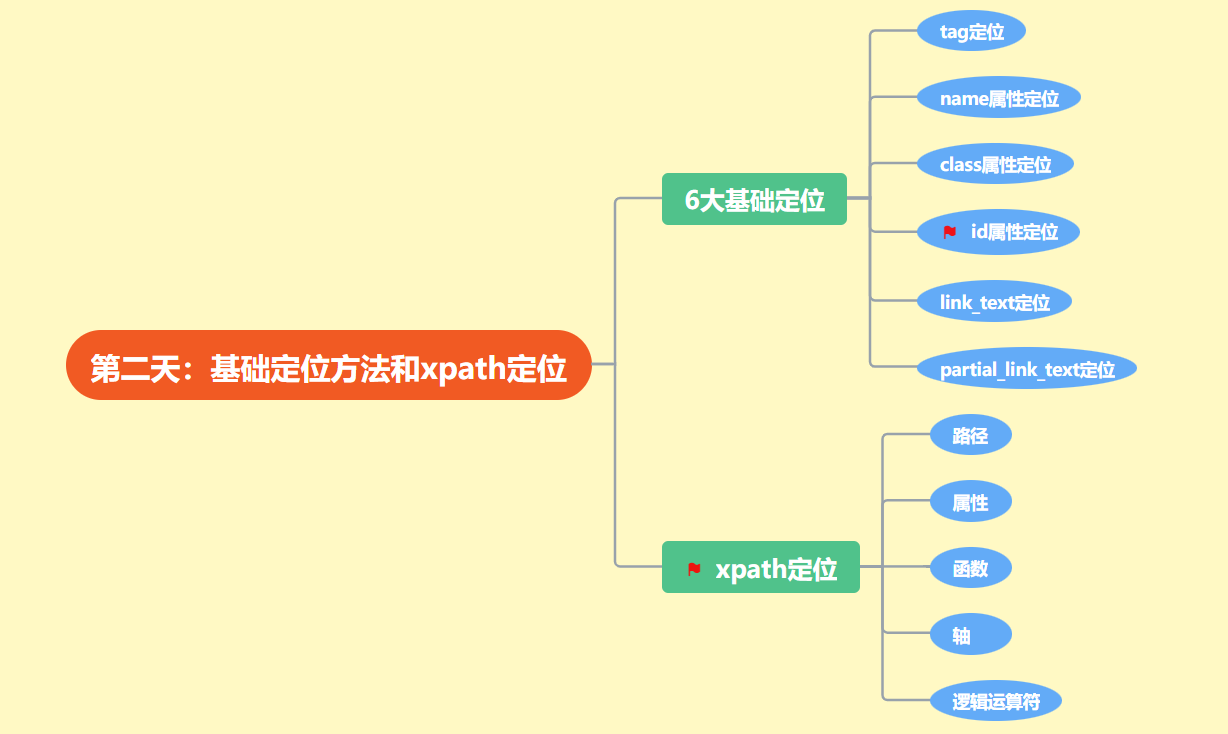
第二部分:6大基础定位
WebDriver对象所有定位方法
这是selenium4.20及以下版本的输出,4.3.0中find_element_by_直接被remove了,包括find_elements_by_
| 对象属性、方法 | 说明 |
|---|---|
| find_element | 通用元素定位方法,找一个元素 |
| find_element_by_class_name | 通过class属性值定位,4.0废弃(打上了删除线,仍然可用) |
| find_element_by_css_selector | 通过css选择器定位,4.0废弃 |
| find_element_by_id | 通过id属性值定位,4.0废弃 |
| find_element_by_link_text | 通过超链接文本定位,4.0废弃 |
| find_element_by_name | 通过name属性值定位,4.0废弃 |
| find_element_by_partial_link_text | 通过部分超链接文本定位,4.0废弃 |
| find_element_by_tag_name | 通过标签名定位,4.0废弃 |
| find_element_by_xpath | 通过xpath定位,4.0废弃 |
| find_elements | 通用元素定位方法,找多个元素,返回列表 |
| find_elements_by_class_name | 同上,找多个元素,返回列表 |
| find_elements_by_css_selector | 同上,找多个元素,返回列表 |
| find_elements_by_id | 同上,找多个元素,返回列表 |
| find_elements_by_link_text | 同上,找多个元素,返回列表 |
| find_elements_by_name | 同上,找多个元素,返回列表 |
| find_elements_by_partial_link_text | 同上,找多个元素,返回列表 |
| find_elements_by_tag_name | 同上,找多个元素,返回列表 |
| find_elements_by_xpath | 同上,找多个元素,返回列表 |
注意事项
| 定位方法 | 含义 | 注意事项 |
|---|---|---|
| tag | 标签名定位 | 因太多重复,基本没用 |
| head中的元素较为特殊 | ||
| name | name属性值定位 | 易重复 |
| 定位到多个,操作的是第一个,所有的find_element方法都是如此 | ||
| class | class属性值定位 | 易重复 |
| 不允许使用复合类名(即多值) | ||
| 多值问题说明https://www.w3school.com.cn/tags/att_standard_class.asp | ||
| id | id属性值定位 | 推荐用 |
| 注意变化的ID | ||
| 注意数字开头的ID | ||
| link_text | a标签的文本定位 | 会重复 |
| 只能是a标签 | ||
| 理解什么是文本 | ||
| partial_link_text | a标签的部分文本定位 | 易重复 |
| 包含的意思 |
-
关于class属性
-
-
class 属性规定元素的类名(classname)。
-
class 属性大多数时候用于指向样式表中的类(class)。不过,也可以利用它通过 JavaScript 来改变带有指定 class 的 HTML 元素。、
-
class 属性不能在以下 HTML 元素中使用:base, head, html, meta, param, script, style 以及 title
-
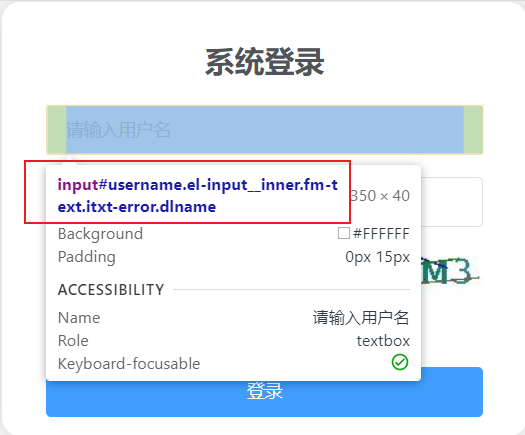
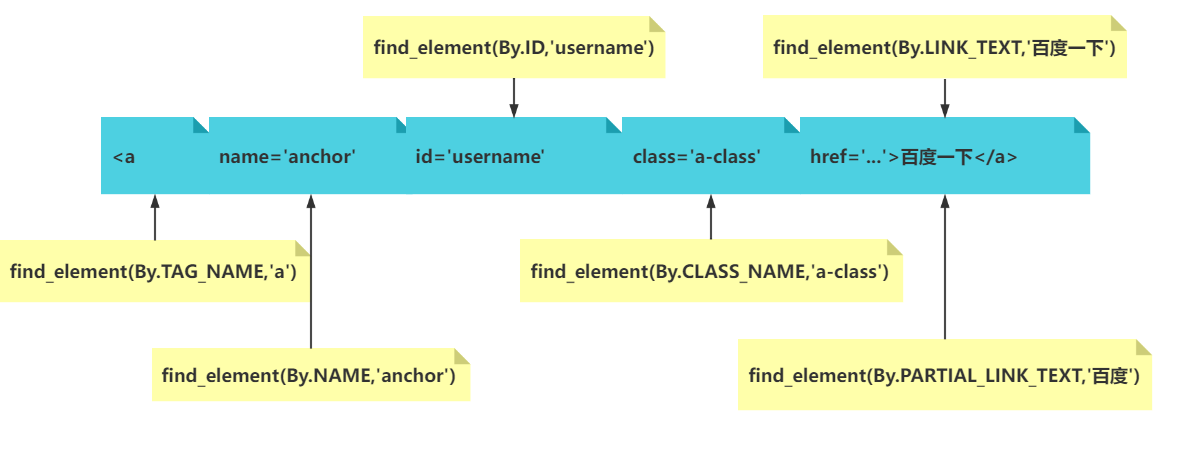
可以给 HTML 元素赋予多个 class,例如:。这么做可以把若干个 CSS 类合并到一个 HTML 元素。
class='aa bb'意思是有2个类,一个类的值是aa,一个类的值是bb(见下图) -
类名不能以数字开头!只有 Internet Explorer 支持这种做法。
-
第三部分:xpath定位
-
xpath是什么?
-
- XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 包含一个标准函数库
- XPath 是 XSLT 中的主要元素
- XPath 是一个 W3C 标准
-
普通语法
名称 表达式 示例 描述 绝对路径 / /html/body/input 从根节点html,逐级往下(不跳跃) 相对路径 // //input 所有的input标签 //* 所有标签 //input[1] 每个父节点下的第一个input标签 //input[last()] 每个父节点下的最后个input标签 //input[last()-1] 每个父节点下的倒数第二个input标签 //input[position()<3] 每个父节点下的前2个input标签 符号 . 当前节点,一般不用 .. //*[@id='username']/.. 父节点,常用于子代元素特征明显父代元素无明显特征的情况 属性法 [@属性='属性值'] //*[@id='username'] id唯一,所以前面的标签名可以不写,但不可省略//* //input[@name='password'] //button[@class='pn vm'] 注意跟by_class_name的区别,此处要传递所有值,不能是部分 其他运算符 //*[@width>700] 对于数字的属性值,还可以用运算符来比较定位 //*[@属性] //*[@style] 具有某个属性的标签 函数 starts-with(@属性名,'属性开头的值') //*[starts-with(@id,'username')] 匹配属性开头的值,处理属性值变化的元素 contains(@属性名,'属性包含的值') //*[contains(@id,'username')] 匹配属性包含的值 text()='文本的值' //a[text()='百度搜索'] 匹配文本的值,可以替代link_text方法 contains(text(),'文本包含的值') //a[contains(text(),'搜索')] 匹配文本包含的值,可以替代partial_link_text方法 -
xpath轴语法
轴名称 结果 ancestor 选取当前节点的所有先辈(父、祖父等)。 ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 attribute 选取当前节点的所有属性。 child 选取当前节点的所有子元素。 descendant 选取当前节点的所有后代元素(子、孙等)。 descendant-or-self 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 following 选取文档中当前节点的结束标签之后的所有节点。 namespace 选取当前节点的所有命名空间节点。 parent 选取当前节点的父节点。 preceding 选取文档中当前节点的开始标签之前的所有节点。 preceding-sibling 选取当前节点之前的所有同级节点。 self 选取当前节点。
注意事项
-
//*[@id='username' and @type='text'] -
xpath语法中的值用单引号或双引号引起来的时候,注意在python代码中要注意区分。
-
xpath的属性不局限于id、name、class,可以是任意属性
-
xpath的class属性需要填写全部值,而不是跟class定位只能填写部分(涉及到底层的封装)
-
xpath官方支持的函数特别多,但不是浏览器都支持的
//*[contains(@id,'username')] #可以 //*[contains(@id,'username')] #可以 //*[ends-with(@id,'username')] #不支持 -
xpath可以替换前面6种定位元素的语法,甚至还有扩充(如非a标签的文本),可以说没有xpath语法定位不到的元素
-
xpath相对是慢的(加载整个DOM)
-
link_text和partial_link_text底层是调用xpath的
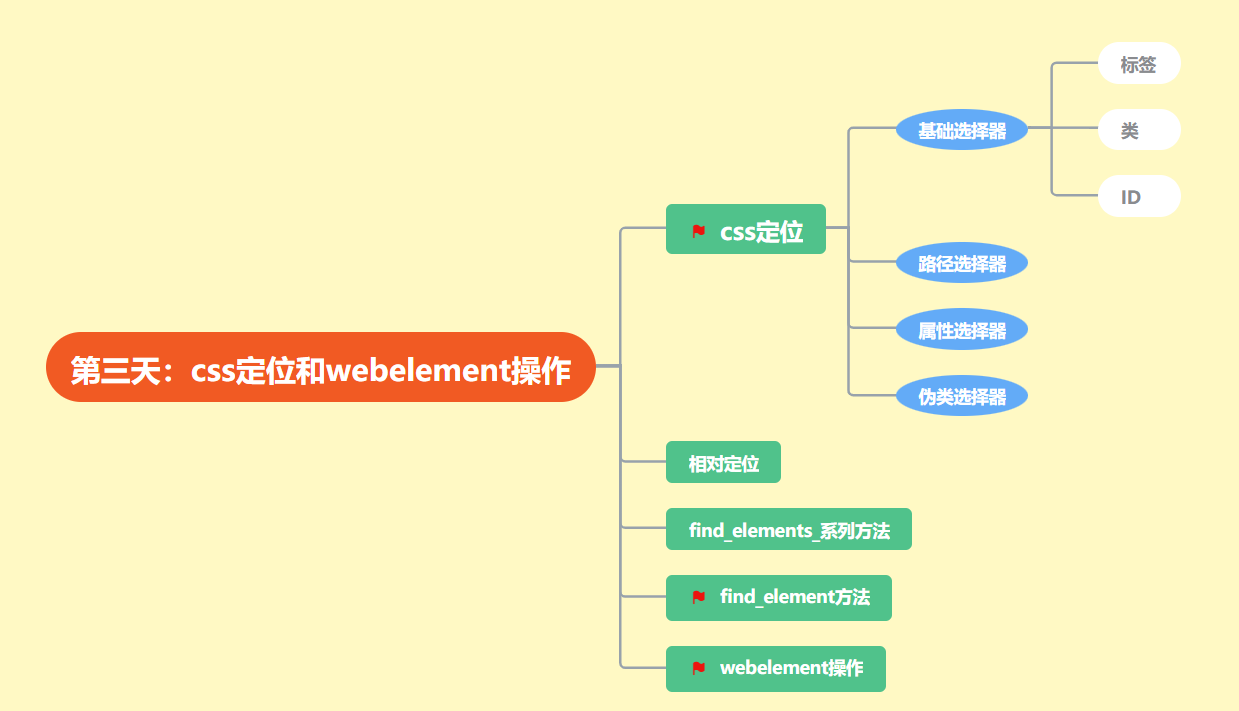
三:css定位和webelement操作(基础)
第一部分:css定位
-
css简介:
-
- CSS 指的是层叠样式表 (Cascading Style Sheets)
- CSS 描述了如何在屏幕、纸张或其他媒体上显示 HTML 元素
- CSS 节省了大量工作。它可以同时控制多张网页的布局
| 名称 | 表达式 | 示例 | 描述 |
|---|---|---|---|
| 类型选择器(标签) | tag_name | p | 所有p标签 |
| id选择器 | #id | #username | id的值为username |
| 类选择器 | .class1.class2 | .pn.vm | class1的值是pn,class2的值是vm |
| tagname#id.class | input#username.pn.vm | class1的值是pn,class2的值是vm,且id的值是username的input标签 | |
| 路径选择器:子代 | nod1>nod2 | html>body>div | html下body下的div标签(子代元素) |
| 路径选择器:后代 | nod1 node2 | html input | html下的任意input标签(后代元素) |
| 路径选择器:相邻弟弟(二弟) | node1+node2 | html>head+body | html下跟head紧挨着的body |
| 路径选择器:弟弟 | node1~node2 | div~p | div与p同级,p在div后面不一定紧挨着 |
| 属性选择器 | [属性名='属性值'] | input[id='username'] | id属性值为username的input标签(id唯一则input可以不写) |
| input[class='el-input__inner fm-text itxt-error dlname'] | clas的属性必须全部填入不能是部分 | ||
| [属性名^='属性值'] | input[name^='username'] | 开头是 | |
| [属性名$='属性值'] | input[name$='ername'] | 结尾是 | |
| [属性名*='属性值'] | input[name*='erna'] | 包含 | |
| 伪类选择器:第几个元素 | tagname:nth-child(n) | body>div:nth-child(3) | body下的第三个标签是div(不是第三个div) |
| 伪类选择器:第一个子元素 | :first-child | body>:first-child | body下的第一个标签 |
| 伪类选择器:最后一个 | :last-child | body>:last-child | body下的最后一个标签 |
| 伪类选择器:倒数第几个元素 | :nth-last-child | body>div:nth-last-child(4) | body下的倒数第四个标签是div(不是第4个div),也不区分大小写 |
| 伪类选择器:唯一元素 | :only-child | input:only-child | 每个节点下的唯一一个input标签(父节点只有一个标签) |
注意事项:
-
css号称速度最快,推荐使用
-
css是firefox和chrome默认显示的语法
-
firefox对css的支持最好
-
css相较xpath无法实现text的定位
-
数字开头的id的值用css的id定位会遇到问题
-
css并不支持多属性用逻辑运算符来组合定位,如[name='username and id='username']是无效的,但他可以这么写
[id='username'][name='username']
Xpath和CSS语法的对比
| 示例 | css | xpath | 说明 |
|---|---|---|---|
| id的值 | #id_value | //*[@id='id_value'] | |
| class的值 | .class1.class2 | //*[@class='all_class_value'] | xpath用属性法要全部写 |
| [class='all_class_value'] | css如果用属性法也要全部写 | ||
| 标签 | tag_name | //tag_name | |
| 绝对路径 | html>body | /html/body | |
| 相对路径 | html div | /html//div | |
| 紧挨的下一个 | div+p | 不支持 | |
| 开头是 | [属性名^=属性开头的值] | //*[starts-with(@属性名,属性开头的值)] | |
| 包含 | [属性名*=属性开头的值] | //*[contains(@属性名,属性包含的值)] | |
| 结尾是 | [属性名$=属性结尾的值] | selenium中不支持 | xpath有ends-with |
| 文本 | 不支持 | //*[text()='文本的值'] | link_text和partial_link_text的底层实现就是xpath |
| 部分文本 | 不支持 | //*[contains(text(),'部分文本的值'] | |
| 下标 | //input[1] | xpath表示每个节点下的第一个input标签(input前可以有非input标签) | |
| input:nth-child(1) | css表示input必须是父节点下的第一个元素 |
动态元素
示例1:这个class='a',只有当前页面才有
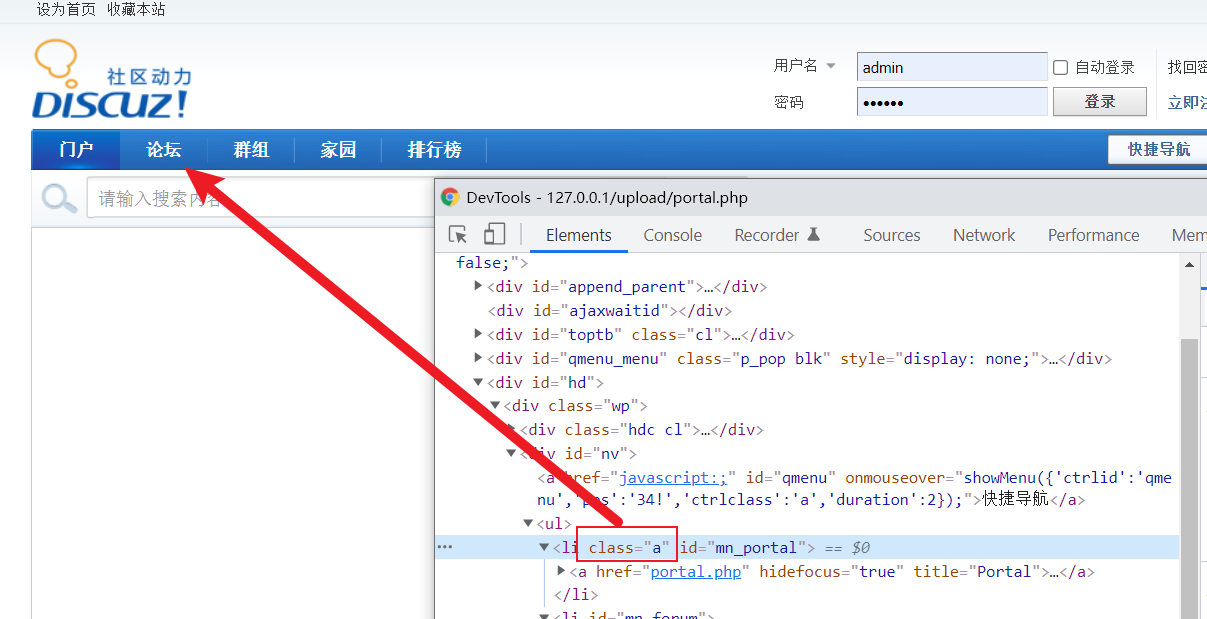
示例2:class='is-active'
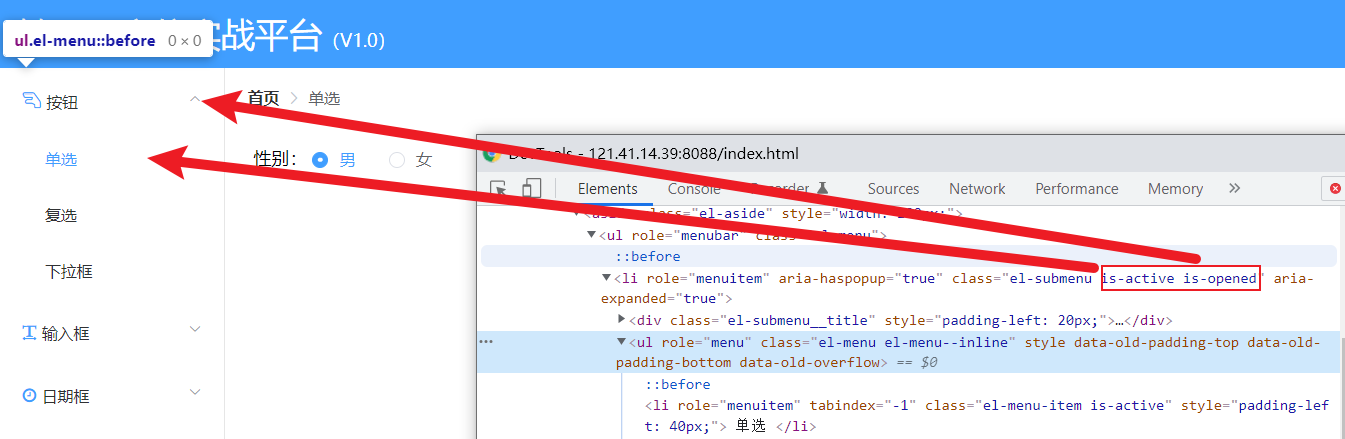
第二部分:find_element_定位
-
源码阅读
def find_element(self, by=By.ID, value=None) -> WebElement: #返回一个webelement对象 默认就是ID定位,value默认为空,意味着value是必须传递的参数 """ Find an element given a By strategy and locator. :Usage: :: element = driver.find_element(By.ID, 'foo') :rtype: WebElement """ if isinstance(by, RelativeBy): #如果by是一个RelativeBy对象 return self.find_elements(by=by, value=value)[0] #调用find_elements方法(后面看相对定位的时候解析) if by == By.ID: #如果是ID定位 by = By.CSS_SELECTOR #改为CSS定位 value = '[id="%s"]' % value #把你写的value替换为[ID='VALUE']的格式 elif by == By.TAG_NAME: #如果是TAG定位 by = By.CSS_SELECTOR #改为CSS定位,啥也不做,因为CSS的语法TAG_NAME就是直接写 elif by == By.CLASS_NAME: by = By.CSS_SELECTOR value = ".%s" % value #如果是CLASS定位,在VALUE前加.,那么你能理解为何之前2个类的时候的报错了吗?如果你非要传多个类呢? elif by == By.NAME: by = By.CSS_SELECTOR value = '[name="%s"]' % value #如果是name定位就改写VALUE为CSS的属性法,跟ID是一样的 return self.execute(Command.FIND_ELEMENT, { 'using': by, 'value': value})['value'] -
实例代码
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('http://121.41.14.39:8088/index.html#/') driver.find_element(value='username').send_keys('a') #ID是默认值可以不传 driver.find_element(By.CLASS_NAME,'el-input__inner.fm-text.itxt-error.dlname').send_keys('b') #非要用classname传递多个值 driver.find_element(By.ID,'username').send_keys('c') #规矩的写法 driver.find_element('id','username').send_keys('d') #直接用str,但有些值你可能记不清楚 username_locator = ('id','username') #写一个定位器 driver.find_element(*username_locator).send_keys('e') #解包 driver.find_element(*['id','username']).send_keys('f') driver.find_element(['id','username']).send_keys('g') #最典型的错误 #selenium.common.exceptions.InvalidArgumentException: Message: invalid argument: 'using' must be a string
第三部分:相对定位
-
在selenium4.0中增加了相对定位(之前叫做友好定位)
-
使用场景:当你用8个定位方法不那么容易定位到的时候,可以尝试用相对定位(前提是相对定位反而方便)
-
selenium实现相对定位的根本是在于它用了JavaScript的 getBoundingClientRect() 方法来获取元素在页面上的大小和位置,从而实现你根据某个元素来定位周边元素的想法。
-
导入
from selenium.webdriver.support.relative_locator import locate_with -
语法
locate_with(By,using).above(webelement或dict) 最终返回一个RelativeBy对象,可以用来定位 #含义是: 根据above()括号内的元素或定位器定位其上面的元素,符合locate_with()括号内的表达式 locate_with(By,using).above(webelement或dict).below(webelement或dict) 链式调用 #含义是: 根据above()括号内的元素或定位器定位其上面的元素,同时根据below()括号内的元素或定位器定位其下面的 符合locate_with()括号内的表达式 -
示例代码1:演示语法
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.relative_locator import locate_with driver =webdriver.Chrome() driver.get('http://121.41.14.39:8088/index.html#/') password_locator = {'id': 'password'} #字典形式,个人觉得比较生僻 which_element1 = locate_with(By.TAG_NAME,'input').below(password_locator) #找密码元素下面的标签为input的元素,返回一个元素的定位器(其实是一个RelativeBy对象) driver.find_element(which_element1).send_keys('hehe') #效果在验证码输入框输入hehe password_webelement = driver.find_element('id','password') #webelement形式,个人觉得比较直观 which_element2 = locate_with(By.TAG_NAME,'input').below(password_webelement) driver.find_element(which_element2).send_keys('haha') #效果在验证码输入框追加输入haha img_locator = {'xpath':'//img'} #验证码图片 which_element = locate_with(By.TAG_NAME,'input').below(password_locator).to_left_of(img_locator) #链式调用 : 最终定位的元素是密码下方,图片左侧,满足条件定位器tag name=input driver.find_element(which_element).send_keys('heihei') ##效果在验证码输入框追加输入heihei -
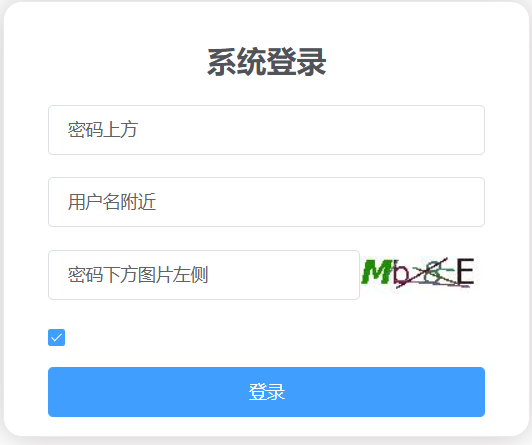
示例代码2:演示上下左右附近5个方法
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.relative_locator import locate_with driver =webdriver.Chrome() driver.get('http://121.41.14.39:8088/index.html#/') ele_password = driver.find_element('id','password') driver.find_element(locate_with(By.TAG_NAME,'input').above(ele_password)).send_keys('密码上方') driver.find_element(locate_with(By.TAG_NAME,'input').below(ele_password)).send_keys('密码下方') ele_img = driver.find_element('xpath','//img') driver.find_element(locate_with(By.TAG_NAME,'input').to_left_of(ele_img)).send_keys('图片左侧') ele_code = driver.find_element('id','code') print(driver.find_element(locate_with(By.TAG_NAME, 'img').to_right_of(ele_code)).tag_name) ele_username = driver.find_element('id','username') driver.find_element(locate_with(By.TAG_NAME,'input').near(ele_username)).send_keys('用户名附近') #效果如图 -
第四部分:find_elements_定位
-
返回对象是列表
-
里面的每个元素都是webelement对象
-
如果要操作元素或者获取元素的属性需要遍历
-
应用场景
-
- 爬虫:往往要获取多组数据
- 批量操作:同类型元素的相同操作
第五部分:webelement操作
WebElement对象所有属性、方法
| 对象属性(方法或类) | 说明 |
|---|---|
| accessible_name | |
| aria_role | |
| clear | 清空 |
| click | 点击 |
| find_element | 元素上找元素 |
| find_element_by_class_name | 同上,未废弃 |
| find_element_by_css_selector | 同上 |
| find_element_by_id | 同上 |
| find_element_by_link_text | 同上 |
| find_element_by_name | 同上 |
| find_element_by_partial_link_text | 同上 |
| find_element_by_tag_name | 同上 |
| find_element_by_xpath | 同上 |
| find_elements | 同上 |
| find_elements_by_class_name | 同上 |
| find_elements_by_css_selector | 同上 |
| find_elements_by_id | 同上 |
| find_elements_by_link_text | 同上 |
| find_elements_by_name | 同上 |
| find_elements_by_partial_link_text | 同上 |
| find_elements_by_tag_name | 同上 |
| find_elements_by_xpath | 同上 |
| get_attribute | 获取元素属性 |
| get_dom_attribute | |
| get_property | |
| id | |
| is_displayed | 是否显示 |
| is_enabled | 是否使能 |
| is_selected | 是否可选 |
| location | 元素位置 |
| location_once_scrolled_into_view | 滚动到可见 |
| parent | |
| rect | 元素矩形 |
| screenshot | |
| screenshot_as_base64 | |
| screenshot_as_png | 元素截图 |
| send_keys | 元素上输入内容 |
| shadow_root | |
| size | 元素大小 |
| submit | 提交元素 |
| tag_name | 元素标签名 |
| text | 元素文本 |
| value_of_css_property | 元素的css属性值 |
示例代码DAY3
验证码破解
from selenium import webdriver
from time import sleep
import ddddocr
driver = webdriver.Chrome()
driver.get('http://121.41.14.39:8088/index.html')
driver.find_element('css selector','#username').send_keys('sq1')
driver.find_element('css selector','#password').send_keys('123')
ele_img = driver.find_element('css selector','img')
ocr = ddddocr.DdddOcr(show_ad=False)
text = ocr.classification(ele_img.screenshot_as_png)
# with open('code.png','wb') as f:
# f.write(ele_img.screenshot_as_png) #bytes类型,可以保存截图
sleep(2)
driver.find_element('css selector','#code').send_keys(text)
sleep(2)
driver.find_element('css selector','#submitButton').click()
四:weddriver操作(一)
第一部分:webdriver基础操作
| 对象属性、方法 | 说明 |
|---|---|
| add_cookie | 添加cookie |
| back | 返回 |
| close | 关闭不退出进程 |
| current_url | 当前URL |
| current_window_handle | 当前窗口句柄 |
| delete_all_cookies | 删除所有cookie |
| delete_cookie | 删除指定cookie |
| desired_capabilities | 能力值 |
| execute_cdp_cmd | 执行cdp命令 |
| execute_script | 执行js代码 |
| forward | 前进 |
| fullscreen_window | 全屏 |
| get | 打开网址 |
| get_cookie | 获取cookie |
| get_cookies | 获取所有cookie |
| get_window_position | 获取窗口位置 |
| get_window_rect | 获取窗口矩形 |
| get_window_size | 获取窗口大小 |
| implicitly_wait | 隐式等待 |
| maximize_window | 最大化窗口 |
| minimize_window | 最小化窗口 |
| name | 浏览器名字 |
| page_source | 页面源码 |
| quit | 退出浏览器进程 |
| refresh | 刷新 |
| save_screenshot | 保存截图 |
| set_page_load_timeout | 设置页面加载超时时间 |
| set_window_position | 设置窗口位置 |
| set_window_rect | 设置窗口矩形 |
| set_window_size | 设置窗口大小 |
| switch_to | 切换到 |
| title | 浏览器标题 |
| window_handles | 窗口句柄 |
第二部分:无头浏览器及option
headless
历史由来:
- Phantomjs4.0中彻底废除了
应用场景:
- 无头的场景,一般先有头测试,再无头运行
- 节省资源
- 不关注正常的操作过程
- 对错误的仍然可以截图
chrome示例代码
from selenium import webdriver
my_option = webdriver.ChromeOptions()
my_option.add_argument('-headless')
driver = webdriver.Chrome(options=my_option)
firefox示例代码
from selenium import webdriver
my_option = webdriver.FirefoxOptions()
my_option.add_argument('-headless')
driver = webdriver.Firefox(options=my_option)
注意事项:
-
浏览器的默认大小不太一样
-
一般建议打开后最大化浏览器
-
不会影响截图
-
注意headless的参数可以是
-headless --headless 但如果是headless,chrome是可以的,但firefox不可以
关于option
示例代码1:免登录
-
user_data_dir的获取可以通过chrome://version得到,注意去掉尾部的default
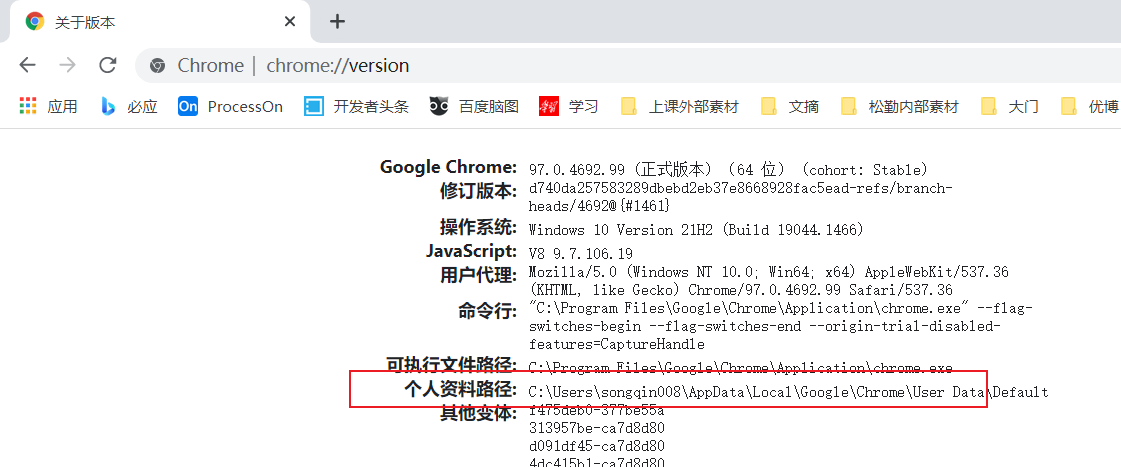
from selenium import webdriver
myoption = webdriver.ChromeOptions()
user_data_dir = r'C:\Users\songqin008\AppData\Local\Google\Chrome\User Data' #我的路径跟你 的不一样
myoption.add_argument(f'--user-data-dir={user_data_dir}') #选项中就有用户数据了
driver = webdriver.Chrome(options=myoption)
driver.get('https://processon.com/') #打开一个网页,注意这个网页你应该要事先登录过
关于CDP
示例代码1:典型的CDP命令
import base64from selenium import webdriverfrom time import sleepdriver = webdriver.Chrome()test_flag = 3if test_flag ==
2000
1: #关闭浏览器,相当于quit driver.execute_cdp_cmd('Browser.close',{})if test_flag ==2: # 截图 driver.get('https://www.baidu.com') res = driver.execute_cdp_cmd('Page.captureScreenshot', {}) with open('test.png', 'wb') as f: img = base64.b64decode(res['data']) f.write(img)if test_flag ==3: # 开网址 cdp_cmd = 'Page.navigate' cdp_para = { "url": "https://cn.bing.com/" } driver.execute_cdp_cmd(cdp_cmd,cdp_para)
第三部分:select元素操作
-
本质上也可以用点击来完成,但selenium提供了API来操作,操作更加方便
-
导入包
from selenium.webdriver.support.select import Select -
方法说明
select_by_visible_text('男') #可见的文本 select_by_value('2') #value属性的值 select_by_index(0) #下拉菜单的第一个选项 deselect_all() #反选所有 -
注意事项:对于select_by_visible_text,可见的文本就是用户见到的文本,但有的同学在使用UI对战平台的下拉示例的时候,可见的文本以为要复制HTML源码,那是有空格的,如果把空格复制进去你就得不到结果,需要
第四部分:键盘模块
-
导入包
from selenium.webdriver import Keys -
源码
class Keys(object): BACKSPACE = u'\ue003' BACK_SPACE = BACKSPACE ENTER = u'\ue007' CONTROL = u'\ue009' -
注意事项
-
- 结合send_keys()发送组合键
- CTRL+A这样的组合键,可以是A或a
- 可以用乘法进行多次操作
- 可以组合文本(如输入信息后+ENTER,变相实现提交功能)
第五部分:鼠标模块
-
导入包
from selenium.webdriver import ActionChains -
语法
#第一种写法:链式写法 ActionChains(driver).动作1.动作2.perform() #第二种写法:分步执行 myaciton = ActionChains(driver) myaciton.动作1 myaciton.动作2 myaciton.perform() -
常见的方法
动作 说明 context_click(self, on_element=None) 右键 double_click(self, on_element=None) 双击 move_to_element(self, to_element) 鼠标移动到某个元素 click(self, on_element=None) 左键 drag_and_drop(self, source, target) 拖拽到某个元素然后松开 drag_and_drop_by_offset(self, source, xoffset, yoffset) 拖拽到某个坐标然后松开 key_down(self, value, element=None) 按下某个键 key_up(self, value, element=None) 松开某个键 move_by_offset(self, xoffset, yoffset) 鼠标从当前位置移动到某个坐标 move_to_element_with_offset(self, to_element, xoffset, yoffset) 移动到距某个元素(左上角坐标)多少距离的位置 release(self, on_element=None) 在某个元素位置松开鼠标左键 send_keys(self, *keys_to_send) 发送某个键到当前焦点的元素 send_keys_to_element(self, element, *keys_to_send) 发送某个键到指定元素 click_and_hold(self, on_element=None) 按住左键不放
五:weddriver操作(二)
第一部分:js操作
https://developer.mozilla.org/zh-CN/docs/Web/API/Document_Object_Model
常见的JS操作
js操作可以再开发者工具的控制台console运行,有自动补齐功能
window
-
window.open() # 打开一个空白页
-
window.open('https://www.jd.com') #打开京东
-
window.scrollTo(x,y)
-
- 配合document.body.scrollHeight和document.body.scrollWidth使用
document
-
document.title
-
document.cookie
-
document.URL
-
document.body.scrollHeight
-
document.body.scrollWidth
-
元素定位
-
- getElementById #通过id的值定位
- getElementsByClassName #通过class的值定位,返回列表
- getElementsByName #通过元素的名字定位,返回列表
- getElementsByTagName #通过元素的标签定位,返回列表
- querySelector #通过css选择器定位
- querySelectorAll #通过css选择器定位,返回列表
-
元素操作:先定位到再操作
-
- document.getElementById('username').value='sq1' #输入sq1这个值
- document.getElementById('username').value='' #clear
- document.querySelector('.pn.vm').click() #点击登录按钮
- document.getElementById('password').type='text' #修改属性值
- document.querySelector("a[href='admin.php']").removeAttribute('target') #移除属性
navigator
- navigator.platform
- navigator.userAgent
- navigator.appName
- navigator.appVersion
location
http://121.41.14.39:8088/index.html#/ 以UI对战平台为例
- location.host #'121.41.14.39:8088'
- location.hostname #'121.41.14.39'
- location.protocol #'http:'
- location.pathname #'/index.html'
其他
- alert('alert')
- confirm('confirm')
- prompt('请输入你的名字')
jquery
- $('#username')
- $('#username').value='sq1'
EXECUTE_SCRIPT方法
-
初级用法
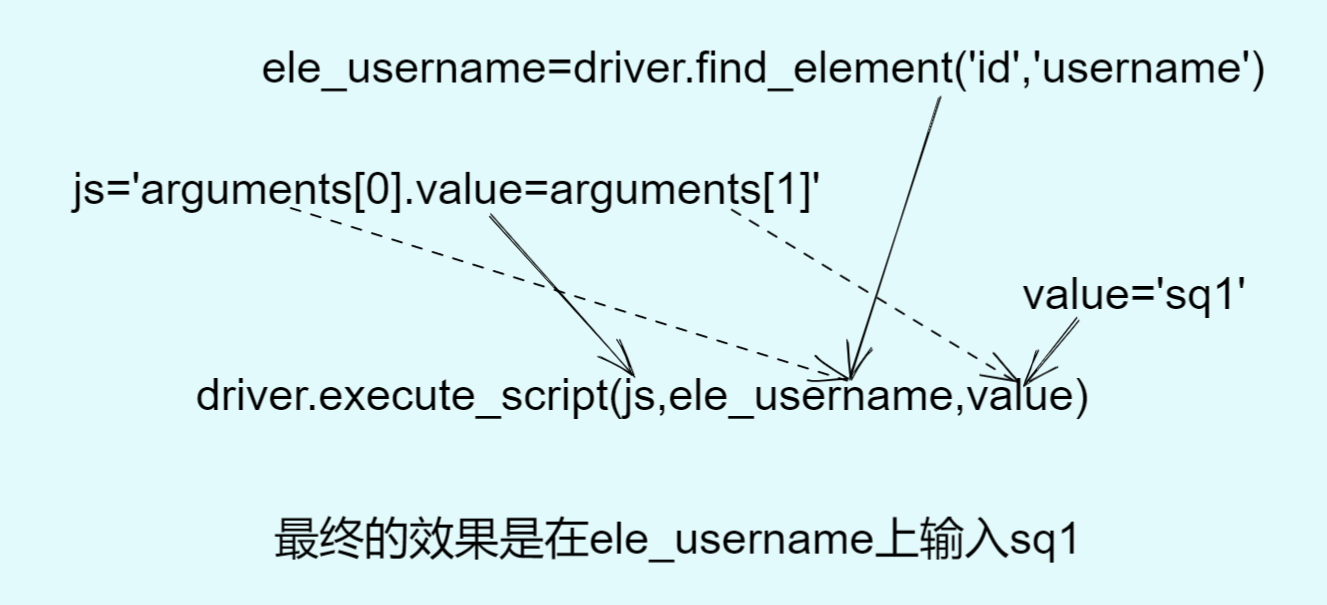
driver.execute_script(js) -
高级用法
#语法 driver.execute_script(js,arg0) driver.execute_script(js,arg0,arg1) -
示例代码
from selenium import webdriver driver = webdriver.Chrome() driver.get("http://127.0.0.1/upload/forum.php") #示例1 # js = 'arguments[0].value="admin"' # ele_username = driver.find_element('id','ls_username') # driver.execute_script(js,ele_username) #示例2 js = 'arguments[0].value=arguments[1]' ele_username = driver.find_element('id','ls_username') value = 'admin' driver.execute_script(js,ele_username,value)
示例代码1:
driver = webdriver.Chrome()driver.get('http://127.0.0.1/upload/forum.php')test_flag = 4if test_flag == 7: # 封装 js20 = "arguments[0].value='admin123'" &nbs
2000
p; ele_username = driver.find_element_by_css_selector('#ls_username') sleep(2) driver.execute_script(js20, ele_username) js21 = "arguments[0].value=arguments[1]" # execute_script(js脚本,第2个参数=>arguments[0],第3个参数=>arguments[1]" driver.execute_script(js21, ele_username, 'world')if test_flag == 6: pass # TODO 修改UI的日期框->日期选择框->转正日期的readonly属性 # ele_date = document.getElementById('conversionTime') # ele_date.readOnly=false #此处的readOnly的O是大写的,跟属性值不同 # js= "ele_date = document.getElementById('conversionTime');ele_date.readOnly=false" # 其实也可以去移除这个属性 # ele.removeAttribute('readonly')if test_flag == 5: js10 = "document.getElementById('ls_username').value='admin'" js11 = "document.getElementsByClassName('px')[1].value='123456'" js12 = "document.getElementById('ls_password').type='text'" driver.execute_script(js10) driver.execute_script(js11) driver.execute_script(js12)if test_flag == 4: js7 = "document.getElementById('ls_username').value='admin'" js8 = "document.getElementsByClassName('px')[1].value='123456'" js9 = "document.getElementsByClassName('pn')[0].click()" driver.execute_script(js7) print(driver<
1000
/span>.find_element_by_id('ls_username').text) driver.execute_script(js8) # driver.execute_script(js9) # BUT UI 和 POLLY都无法实现 ,跟前端的控制有关系 # 可以输入,可以点击,但是就是无法登录UI和POLLY # querySelector find_element_by_CSS #document.querySelector('#ls_username') # querySelectorAll find_elements_by_CSSif test_flag == 3: # 滚动条 # 如果要逐步滚动 每次滚动的值不一样 driver.set_window_size(500, 500) sleep(2) js3 = 'window.scrollTo(0,10000)' # 滚动到底部 给y一个大值 # document.body.scrollHeight 精准 driver.execute_script(js3) sleep(2) js4 = 'window.scrollTo(0,0)' # 滚动到顶 driver.execute_script(js4) sleep(2) js5 = 'window.scrollTo(10000,0)' # document.body.scrollWidth替代 driver.execute_script(js5) sleep(2) driver.execute_script(js4) sleep(2) js6 = 'window.scrollTo(0,document.body.scrollHeight)' driver.execute_script(js6)if test_flag == 2: js1 = 'return document.title' # return不能少 print(driver.execute_script(js1)) js2 = 'return document.URL' print(driver.execute_script(js2))if test_flag == 1: # 打开网页 driver.execute_script('window.open()')
第二部分:三种等待
强制等待
-
语法
from time import sleep sleep(2) -
固定的等待
-
常用于演示、调试,初学观察效果等
-
实际项目中一般不建议在定位元素的时候使用,不可靠(网络的好坏导致等待时间不确定)
-
但也有特例要用到
-
- 比如界面操作完要关闭,但是最后你提交了一些操作,如果非常快的退出浏览器有时候会丢失请求,那就需要你强制等待一定时间,这个跟隐式等待还是显式等待都无关。
隐式等待
-
语法
driver.implicitly_wait(最大等待时间) #单位是秒 -
参数是最大等待时间,只要在此规定时间内整个页面全部加载完成即可操作元素。
-
设置一次,全局(在对应浏览器的整个生命周期内)生效,对所有元素都生效(一视同仁),所以一般都建议放在浏览器打开后立即设置
-
但是要注意的是,实际操作过程中你所需要定位的元素可能先加载了,但界面上的其他元素尚未完全加载,你也只能等待,无法操作该元素,而整个页面的加载完成可能会浪费你的等待时间
-
对alert、窗口、元素的属性都无法识别
显式等待
-
显式等待 是Selenium客户可以使用的命令式过程语言。它们允许您的代码暂停程序执行,或冻结线程,直到满足通过的 条件 。只要这个条件返回一个假值,它就会以一定的频率一直被调用,直到等待超时。
-
由于显式等待允许您等待条件的发生,所以它们非常适合在浏览器及其DOM和WebDriver脚本之间同步状态。
-
针对隐式等待的浪费时间问题,显式等待就更加有针对性。它是针对某个(或某组)具体的元素或者某种行为(不仅仅是元素定位!),看它是否具备了一定的特征,就开始有所动作了。
-
显式等待也有最大等待时间,还提供了轮训间隔,等待某个条件成立或不成立。
-
按照官方说法,不能将隐式等待和显式等待放在一起,会产生意想不到的结果。
-
导入包
from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC -
语法
#1. 直接调用 WebDriverWait(driver, 超时时长, 调用频率(可选,有默认值), 忽略异常(可选,有默认值)).until(可执行方法, 超时时返回的信息) #2. 分开调用 mywait = WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None) mywait.until(method,msg) mywait.until_not(method,msg) -
WebDriverWait参数说明
-
- driver:浏览器实例
- timeout:最大超时时间,单位是秒
- poll_frequency:轮询的频率,默认0.5秒
- ignored_exceptions:超时后的异常信息
-
until和until_not说明
-
- 直到该方法成立或不成立,如果超时会抛出后面的msg
- selenium4.0中都是函数形式的存在
| 方法 | 传参 | 返回 | 含义 |
|---|---|---|---|
| title_is | title | True/False | 传入预期的浏览器标题,判断是否是当前的浏览器标题 |
| title_contains | title | True/False | 传入预期的浏览器标题的部分,判断是否在当前的浏览器标题中 |
| presence_of_element_located | locator | webelement | 传入带定位元素的定位器,找到就返回webelement对象,否则就超时异常 |
| url_contains | url | True/False | 传入预期的浏览器的url的部分,判断是否在当前页面url中 |
| url_matches | pattern | True/False | 传入预期的浏览器的url的模式,如果匹配当前的url就返回True,否则返回False |
| url_to_be | url | True/False | 传入预期的浏览器的url,判断是否是当前的URL,完全匹配返回True |
| url_changes | url | True/False | 传入预期的浏览器的url,判断是否不是当前的URL,不是(改变了)就返回True |
| visibility_of_element_located | locator | webelement/False | 传入一个元素定位器,如果元素可以被定位到且可见(.is_displayed() ==True),那么返回webelement,否则是False |
| visibility_of | webelement | webelement/False | 同上,就是传递的参数不同 |
| presence_of_all_elements_located | locator | webelement组成的列表 | 用来定位多个元素的,find_element和find_elements的区别 |
| visibility_of_any_elements_located | locator | 可见的webelement组成的列表 | 传递一个locator,得到一组元素,这些元素必须满足is_displayed()属性值为True |
| visibility_of_all_elements_located | locator | 可见的webelement组成的列表/False | 只要有一个元素不可见就返回False,都可见就返回这些元素组成的列表 |
| text_to_be_present_in_element | locator,text_ | True/False | 传入一个locator用来定位元素,判断传入的text_是否在定位到的元素的text中(包含关系) |
| text_to_be_present_in_element_value | locator,text_ | True/False | 传入一个locator用来定位元素,判断传入的text_是否在定位到的元素的value属性中(包含关系) |
| text_to_be_present_in_element_attribute | locator, attribute_, text_ | True/False | 传入一个locator用来定位元素,如果没有指定的attribute_就返回False,如果有就看其值中是否包含text_ |
| frame_to_be_available_and_switch_to_it | locator | True/False | 这个locator有点特殊,可以是索引可以是webelement,也可以是传统的('id','username')的形式,切换成功就返回True,没有找到Frame就返回False |
| invisibility_of_element_located | locator | True/False/webelement | 如果传入的locator指向的元素的is_displayed是False(不可见)则返回元素,否则返回False,当没有这个元素(捕获到无元素或StaleElementReferenceException)的时候返回True,本质是元素存在不可见或 |
| invisibility_of_element | element | True/False/webelement | 就是上面的方法,只是参数名改为了元素(即可以是find_element的结果) |
| element_to_be_clickable | mark | webelement/False | mark是locator或者webelement,如果这个element存在且可见(is_displayed)并且使能(is_enabled)才返回该元素 |
| staleness_of | element | True/False | 如果报错StaleElementReferenceException,就返回True,否则is_enabled()为真就返回False |
| element_to_be_selected | element | True/False | 元素被选中(is_selected为真)就返回True,未被选中则返回False |
| element_located_to_be_selected | locator | True/False | 跟上面的方法不同的是传递的是locator |
| element_selection_state_to_be | element, is_selected | True/False | 看元素的选中状态,如果是你传递的is_selected的值就返回True,否则返回False,is_selected可以为真或假 |
| element_located_selection_state_to_be | locator, is_selected | True/False | 类似上面的函数,传递的是locator,如果捕获到StaleElementReferenceException异常则返回False |
| number_of_windows_to_be | num_windows | True/False | 传入期望的窗口数(数字!),如果现在是给定的窗口数就True,否则False |
| new_window_is_opened | current_handles | True/False | 如果当前窗口的句柄数量比之前多就返回True,否则False |
| alert_is_present | 无参数 | driver.switch_to.alert/False | 如果打开了alert,并切换过去,如果超时无法切换报错NoAlertPresentException,则返回False |
| element_attribute_to_include | locator, attribute_ | True/False | 如果传入的locator定位到的元素包含给定的属性则返回True,否则返回False |
| any_of | 多个预期条件*expected_conditions | 跟传入的条件有关,可能是webelement,可能是True | 只要有一个条件返回了非空的值,就返回它(跟第一个满足条件的条件有关) |
| all_of | 多个预期条件*expected_conditions | False/列表,列表由每个条件的结果组成, | 只要有一个条件空值,就返回False,否则就添加到列表中 |
| none_of | 多个预期条件*expected_conditions | False/True | 只要有一个条件成立(返回了非空数据,如False),None_of就返回False,都不成立才返回True |
注意事项
- 对于locator参数,其值为一个元组!如('id','username'),前者是selenium.webdriver.common.by.By类中的值(8个属性),后者是具体元素的属性值。
- 这个类和
presence_of_element_located(locator)有点像,但后者只强调元素存在于DOM树中,可见不可见无所谓,而前者要求必须高和宽必须都大于0,因此后者在性能上会稍微快一点点。 - visibility_of(element)看似简单,实则在等待的时候find本身可能会有问题而跳过轮询,一般还是推荐使用visibility_of_element_located(locator)
简易代码
def color_is(your_color):
def _predicate(person):
return person.color == your_color
return _predicate
class China:
color = 'yellow'
wuxianfeng = China()
print(color_is('yellow')(wuxianfeng))
print(color_is('black')(wuxianfeng))
示例代码1:不用expected_conditions的实例
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Chrome()
driver.get('http://127.0.0.1/upload/forum.php')
wait = WebDriverWait(driver,timeout=5,poll_frequency=0.5)
if wait.until(lambda x:x.find_element_by_id('ls_username')):
print('找到了id=ls_username的元素')
示例代码2:until源码解析及实例
-
until源码
def until(self, method, message=''): """Calls the method provided with the driver as an argument until the \ return value does not evaluate to ``False``. :param method: callable(WebDriver) :param message: optional message for :exc:`TimeoutException` :returns: the result of the last call to `method` :raises: :exc:`selenium.common.exceptions.TimeoutException` if timeout occurs """ screen = None stacktrace = None end_time = time.time() + self._timeout #计算轮询结束时间 print(f'现在是{time.ctime()},进入轮询') while True: #循环开始 try: value = method(self._driver) #调用method,传入参数self._driver if value: return value except InvalidSelectorException as e: raise e except self._ignored_exceptions as exc: screen = getattr(exc, 'screen', None) stacktrace = getattr(exc, 'stacktrace', None) print(f'我即将等待{self._poll}秒,现在是{time.ctime()}') time.sleep(self._poll) if time.time() > end_time: print(f'现在是{time.ctime()},退出轮询') break raise TimeoutException(message, screen, stacktrace) -
- 观测timeout的效果
- 观测poll_frequency的效果
- 在过程中修改HTML中用户名id的值为ls_usernam,抬高timeout的值,能看到改对后会立即停止(检测到了)
示例代码3:text_to_be_present_in_element
-
方法的作用:检测元素的文本是否存在指定的内容
-
- 传参:第一个是locator,第二个是包含的文本
- 返回:如果存在了就返回True,否则返回False
-
测试步骤
-
- 延长超时时间和轮询时间,在打开网页后,手工修改指定元素的文本
-
实例代码
from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome() driver.get('http://127.0.0.1/upload/forum.php') dest_text = '软件下载中' try: wait = WebDriverWait(driver, 10, 1) print('最开始元素的文本', driver.find_element_by_css_selector('.lk_content.z p').text) wait.until(EC.text_to_be_present_in_element(('css selector','.lk_content.z p'), dest_text)) print('现在元素的文本', driver.find_element_by_css_selector('.lk_content.z p').text) except: print(f'元素中没有出现文本:{dest_text}') finally: print('2s后关闭浏览器') driver.quit()
第三部分:三种切换
alert切换
-
alert()函数所使用的弹出框是浏览器系统对象而不是网页文档对象!alert()弹出框会阻断JavaScript代码的执行。
-
注意不是所有的弹出框都是alert,比较简单的方法,就是看弹出框的元素是否能定位,如果能定位就不是alert,如果没有任何元素提示那基本就是alert。如下图(某个同学的截图,他以为是alert)。
-
弹窗的三种形式:alert、conform、prompt
-
方法
driver.switch_to.alert.方法 accept() #确定,alert只能用他 dismiss() #取消,alert、confirm、prompt都有用到 send_keys() #输入内容,prompt需要用到 -
alert的另外一种处理方法
from selenium.webdriver.common.alert import Alert Alert(driver). 跟accept() 跟dismiss() 跟send_keys()
示例代码1
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.alert import Alert
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get(r'D:\pythonProject\AutoSelenium\第6次课_1215_webdriver高级操作(三)和PO初识\test.html')
test_flag = 5
if test_flag==5:
# 稳定的切换
# 问题: 你点击了alert之后你立即去accept等操作,有可能会无法及时弹出alert
# 面试题:如果定位不到元素,等待
driver.find_element('id','confirm').click()
sleep(2) #为了演示
alert = WebDriverWait(driver,5,0.5).until(EC.alert_is_present())
alert.accept()
if test_flag==4: #另外一种实现
driver.find_element('id','confirm').click()
sleep(2)
Alert(driver).accept() #不展开
if test_flag ==3:
driver.find_element('id','prompt').click()
sleep(2)
driver.switch_to.alert.send_keys('helloworld') #输入无显示
sleep(2)
driver.switch_to.alert.accept() #这里能看到helloworld
if test_flag ==2:
driver.find_element('id','confirm').click()
sleep(2)
driver.switch_to.alert.dismiss() #输出你选择了取消
if test_flag ==1:
driver.find_element('id','alert').click()
sleep(2)
driver.switch_to.alert.accept()
frame切换
-
frame的识别:devtools种console界面的top;xpath语法定位iframe
-
方法
driver.switch_to.frame(frame_reference) frame_reference可以是 1. frame元素的id属性的值(若有) 2. frame元素的name属性的值(若有) 3. frame元素的索引 #注: 第一个frame的索引是0 4. frame元素本身(find_element得到的对象) driver.switch_to.parent_frame() #父框架,相当于linux下的.. driver.switch_to.default_content() #默认的路径,相当于linux下的~(在html中其实是/) -
html5去掉了frame和frameset,而iframe是需要切换的,而且有可能可以嵌套
示例代码:
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get(r'D:\pythonProject\AutoTest\AutoSelenium4\第6次课_1215_webdriver高级操作(三)和PO初识\test.html')
# 1. 先在外层写一个用户名admin1
driver.find_element('id','uname').send_keys('admin1')
sleep(2)
# 2. 在里面写一个用户名admin2
driver.switch_to.frame('nf') #name属性的值
driver.find_element('id','username').send_keys('admin2')
sleep(2)
# 3. 再到外层写一个用户名admin3
driver.switch_to.default_content()
driver.find_element('id','uname').clear()
driver.find_element('id','uname').send_keys('admin3')
sleep(2)
# 4. 再在里面写一个用户名admin4
driver.switch_to.frame('if') #id属性的值
driver.find_element('id','username').clear()
driver.find_element('id','username').send_keys('admin4')
sleep(2)
# 5. 再在外面写一个用户名admin5
driver.switch_to.parent_frame()
driver.find_element('id','uname').clear()
driver.find_element('id','uname').send_keys('admin5')
sleep(2)
# 6. 再在里面写一个用户名admin6
driver.switch_to.frame(driver.find_element('id','if')) #webelement的方式
driver.find_element('id','username').clear()
driver.find_element('id','username').send_keys('admin6')
sleep(2)
# 7. 再在外面清空
driver.switch_to.parent_frame()
driver.find_element('id','uname').clear()
sleep(2)
# 8. 再在里面写一个用户名admin8
driver.switch_to.frame(0)
driver.find_element('id','username').clear()
driver.find_element('id','username').send_keys('admin8')
示例代码2:稳定的frame切换
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get(r'D:\pythonProject\AutoTest\AutoSelenium4\第6次课_1215_webdriver高级操作(三)和PO初识\test.html')
mywait = WebDriverWait(driver,5,0.5)
test_flag = 2
if test_flag ==1:
frame_locator = ('id', 'if') #driver.switch_to.frame(webelement)
mywait.until(EC.frame_to_be_available_and_switch_to_it(frame_locator)) #已经切换了
# driver.switch_to.frame('if') 这句话不对的, 已经切换了,再在if框架中去找if框架!没有了!
if test_flag == 2: #driver.switch_to.frame(id的值)
frame_ele = driver.find_element('id','if')
mywait.until(EC.frame_to_be_available_and_switch_to_it(frame_ele)) #已经切换了
driver.find_element('css selector','#username').send_keys('sq1')
window切换
-
方法
switch_to.window(window_name) window_name可以是窗口的名字或window handle(窗口句柄) driver.current_window_handle #当前窗口的句柄 driver.window_handles #当前的窗口的句柄列表 -
注意事项:
-
-
有时候点击后无法立即产生新的窗口
-
产生的新的窗口不在列表的最后
-
有的同学会有疑问,我怎样才能关闭多余的窗口呢,切换过去关闭?那自己不是没了嘛?其实是没任何问题的!不能用quit,用close!driver还在就会切换!
from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get('http://121.41.14.39:8088/index.html') first_win = driver.current_window_handle #比如要保留的是第一个窗口,那就记录下来 sleep(2) driver.execute_script('window.open("https://www.baidu.com")') #打开新的窗口 cur_wins = driver.window_handles #当前的所有窗口 driver.switch_to.window(cur_wins[-1]) #切换到新的窗口(假设就是2个窗口,多个要遍历,而且新开的就在最后) sleep(2) driver.close() #切换过去后关闭掉 driver.switch_to.window(first_win) #切换到你要保留的那个窗口 print(driver.current_url) driver.find_element('id','username').send_keys('123')
-
示例代码1:稳定的window切换
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome() #在此处就打开了一个窗口
old_win = driver.current_window_handle #字符串类型,CDwindow-B8FEABE1EA1CF4A90BA60F6FAA91C074
old_wins = driver.window_handles
print(driver.window_handles) #列表,里面塞的是window_handle
driver.get(r'D:\pythonProject\AutoTest\AutoSelenium4\第6次课_1215_webdriver高级操作(三)和PO初识\test.html')
driver.find_element('link text','百度一下').click()
#1. 点击后不一定立即出现,稳定切换
mywait = WebDriverWait(driver,5,0.5)
# if mywait.until(EC.new_window_is_opened(old_wins)):
# # print(driver.window_handles) #此时是多个句柄
# driver.switch_to.window(driver.window_handles[-1])
if mywait.until(EC.number_of_windows_to_be(2)):
driver.switch_to.window(driver.window_handles[-1])
# # TODO 新增的窗口不一定是最后一个元素,怎么办?
driver.find_element('css selector','#kw').send_keys('松勤') #百度搜索输入框
示例代码2:稳定的切换,处理不是最后一个元素
from selenium import webdriver
from time import sleep
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
old_win = driver.current_window_handle
old_wins = driver.window_handles
print(driver.window_handles)
driver.get(r'D:\pythonProject\AutoTest\AutoSelenium4\第6次课_1215_webdriver高级操作(三)和PO初识\test.html')
driver.find_element('link text','百度一下').click()
mywait = WebDriverWait(driver,5,0.5)
if mywait.until(EC.number_of_windows_to_be(2)):
#此时已经有多个窗口了
for win in driver.window_handles[::-1]: #遍历当前多窗口的列表,因为一般都是倒数的,所以从后面遍历
if win not in old_wins: #如果不在老窗口列表中就表示是新的
driver.switch_to.window(win) #切换
break #退出循环,其他的没必要再处理了
driver.find_element('css selector','#kw').send_keys('松勤') #百度搜索输入框
第四部分:文件上传
-
input标签的文件上传直接send_keys即可
-
非input标签的解决方案
-
-
pywinauto
from pywinauto.keyboard import send_keys time.sleep(3) send_keys(r'd:\1.png') # 回车操作 send_keys('{VK_RETURN}') -
pywin32
import win32com.client sh = win32com.client.Dispatch('WScript.shell') time.sleep(2) #这个不加有时候不行 sh.Sendkeys(r'd:\1.png'+'\n') -
pyautogui
import pyautogui time.sleep(2) pyautogui.typewrite(r'"d:\1.png" "d:\2.png"') #有时候会与系统输入法冲突,可以改写位大写的D试试。 pyautogui.keyDown('enter') pyautogui.keyUp('enter')
-
-
示例代码
# Author: wuxianfeng # Company: songqin # File: 第5个脚本_文件上传.py # Date: 21-12-15 # Time: 下午 9:16 print() ''' 知识点: 1. input标签就直接send_keys 2. 非input标签:第三方库来处理 2.1 pyautogui ✓✓ 2.2 pywinauto ✓ 2.3 pywin32 ''' from selenium import webdriver from time import sleep driver = webdriver.Chrome() driver.get('http://121.41.14.39:8088/index.html#/') driver.find_element('id', 'username').send_keys('sq1') driver.find_element('id', 'password').send_keys('123') driver.find_element('id', 'code').send_keys('999999') driver.find_element('id', 'submitButton').click() sleep(2) # 1. 点击文件上传 driver.find_element('xpath', "//span[contains(text(),'文件上传')]").click() sleep(2) test_flag = 2 if test_flag == 1: # 点击单文件上传 driver.find_element('xpath', "//li[contains(text(),'单文件上传')]").click() sleep(1) driver.find_element('css selector', '#cover').send_keys(r'd:\1.txt') if test_flag == 2: # 点击单文件上传非input driver.find_element('xpath', "//li[contains(text(),'非input')]").click() sleep(1) driver.find_element('css selector', '.el-icon-upload').click() sleep(1) import win32com.client sh = win32com.client.Dispatch('WScript.shell') # 注册组件,对话框,excel应用就不是他, sleep(2) sh.Sendkeys(r'd:\1.txt' + '\n') # TODO 多个文件操作 if test_flag == 3: # 点击单文件上传非input #建议深入了解下pyautogui # 1. 定位到两个,处理第一个 driver.find_element('xpath', "//li[contains(text(),'非input')]").click() sleep(1) driver.find_element('css selector', '.el-icon-upload').click() sleep(1) # 此处的延迟无法用隐式、显式来处理,不在浏览器上,windows提供的对话框 import pyautogui pyautogui.typewrite(r'D:\1.txt') # 有时会跟输入法有关 pyautogui.press('enter') if test_flag == 4: # 点击单文件上传非input driver.find_element('xpath', "//li[contains(text(),'非input')]").click() sleep(1) driver.find_element('css selector', '.el-icon-upload').click() sleep(1) from pywinauto.keyboard import send_keys send_keys(r'D:\1.txt') send_keys('{ENTER}') if test_flag == 5: # driver.find_element('xpath', '//*[contains(text(),"多文件上传")]').click() driver.find_element('css selector', '.el-upload__text').click() sleep(1) import pyautogui pyautogui.typewrite(r'"d:\1.jpg" "d:\2.jpg" ') sleep(2) pyautogui.press('enter') sleep(5) driver.quit()
六:Grid不完全操作指南
- 本文的grid是以4.0为例的,如果你要学习3.0系列的grid请移步

下载
- https://github.com/SeleniumHQ/selenium/releases
- 本文以下面的jar为例
目的和主要功能
- 为所有的测试提供统一的入口
- 管理和控制运行着浏览器的节点/环境
- 扩展
- 并行测试
- 跨平台(操作系统)测试
- 负载测试
通常来说,有2个原因你需要使用Grid。
- 在多种浏览器,多种版本的浏览器,不同操作系统里的浏览器里执行你的测试
- 缩短完成测试的时间
组件

路由
路由负责将请求转发到正确的组件.
它是Grid的入口点, 所有外部请求都将由其接收. 路由的行为因请求而异. 当请求一个新的会话时, 路由将把它添加到新的会话队列中. 分发器定期检查是否有空闲槽. 若有, 则从新会话队列中删除第一个匹配请求. 如果请求属于存量会话, 这个路由将会话id发送到会话表, 会话表将返回正在运行会话的节点. 在此之后, 路由将 将请求转发到节点.
为了更好地发挥效力, 路由通过将请求发送到组件的方式, 来平衡Grid的负载, 从而使处理过程中不会有任何的过载组件.
分发器
分发器知道所有节点及其功能. 它的主要作用是接收新的会话请求 并找到可以在其中创建会话的适当节点. 创建会话后, 分发器在会话集合中存储会话ID与正在执行会话的节点之间的关系.
节点
一个节点可以在网格中出现多次. 每个节点负责管理其运行机器的可用浏览器的插槽.
节点通过事件总线将其自身注册到分发服务器, 并且将其配置作为注册消息的组成部分一起发送.
默认情况下, 节点自动注册其运行机器路径上的 所有可用浏览器驱动程序. 它还为基于Chromium的浏览器和Firefox的 每个可用CPU创建一个插槽. 对于Safari和Internet Explorer, 只创建一个插槽. 通过特定的配置, 它可以在Docker容器或中继命令中运行会话
节点仅执行接收到的命令, 它不进行评估、做出判断或控制任何事情. 运行节点的计算机不需要与其他组件具有相同的操作系统. 例如, Windows节点可以具有将Internet Explorer作为浏览器选项的功能, 而在Linux或Mac上则无法实现.
会话表
会话表是一种数据存储的方式, 用于保存会话id和会话运行的节点的信息. 它作为路由支持, 在向节点转发请求的过程中起作用. 路由将通过会话表获取与会话id关联的节点.
新会话队列
新会话队列以先进先出的顺序保存所有新会话请求. 其具有用于设置请求超时和请求重试间隔的可配置参数.
路由将新会话请求添加到新会话队列并等待响应. 新会话队列定期检查队列中的任何请求是否已超时, 若有,则请求将被拒绝并立即删除.
分发器定期检查是否有可用槽. 若有, 分发器将为第一个匹配的请求索取新会话队列. 然后分发器会尝试创建新的会话.
一旦请求的功能与任何空闲节点槽匹配, 分发器将尝试获取可用槽. 如果没有空闲槽, 分发器会要求队列将请求添加到队列前面. 如果请求在重试或添加到队列头时超时, 则该请求将被拒绝.
成功创建会话后, 分发器将会话信息发送到新会话队列. 新会话队列将响应发送回客户端.
事件总线
事件总线充当节点、分发服务器、新的会话队列器和会话表之间的通信路径. 网格通过消息进行大部分内部通信, 避免了昂贵的HTTP调用. 当以完全分布式模式启动网格时, 事件总线是应该启动的第一个组件.
配置
Standalone 单机模式
-
下载好selenium-server-.jar,然后一条命令启动即可
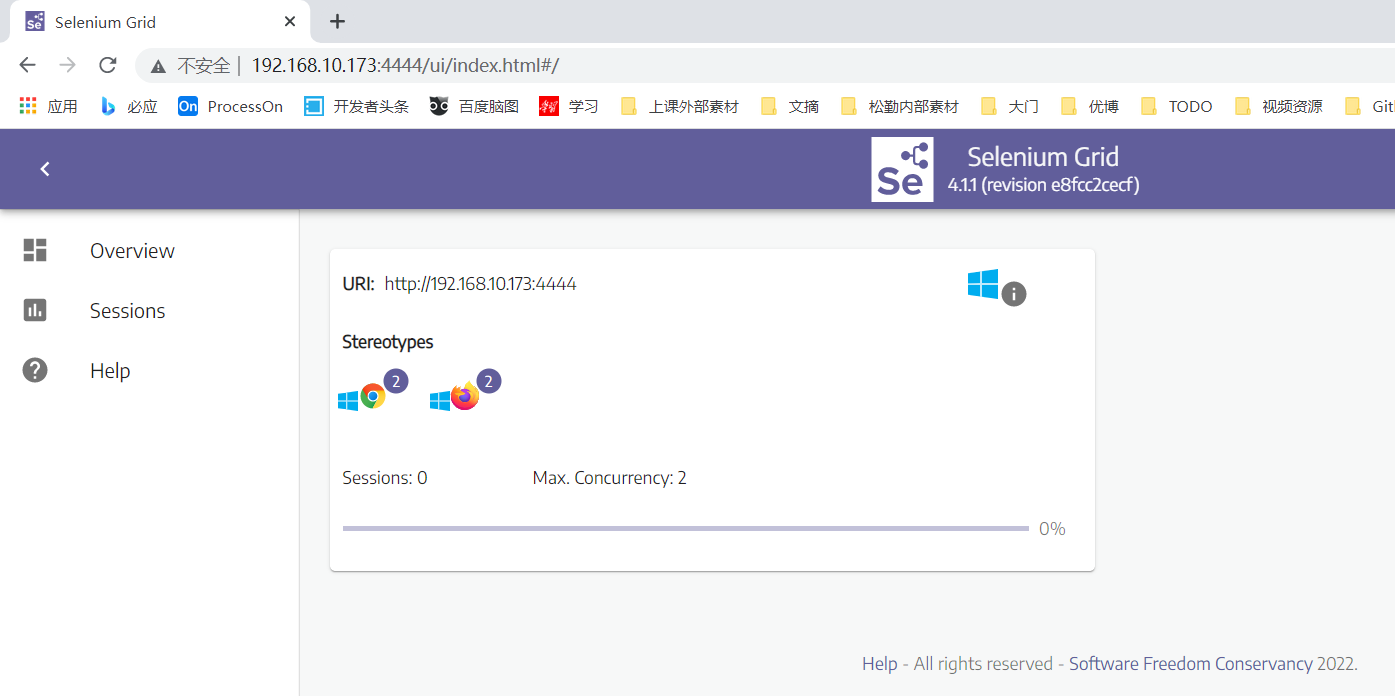
java -jar selenium-server-.jar standalone -
可以打开网页,输入IP:4444/ui/index.html#/看到如下界面
-
可以看到默认是提供了2个firefox和2个chrome实例(注意需要你有对应的webdriver,没有的话,也不会检测到,个数跟你操作系统的CPU逻辑处理器的个数有关)
-
测试代码
from selenium import webdriver option = webdriver.ChromeOptions() driver = webdriver.Remote(command_executor='http://192.168.10.173:4444', #此处的ip地址是运行standalone的节点IP地址,4444是默认端口,可以更改 options=option) driver.get('https://www.baidu.com') from time import sleep sleep(5) driver.quit() -
- 如果最后不退出,那么就等待会话超时(亦可通过参数--session-timeout来调整时间)后方可使用该实例
HUB-NODE(S)模式
-
在该模式下,hub包括了以下所有组件的功能
Router Distributor Session Map New Session Queue Event Bus -
你只需两条命令分别启动HUB和NODE即可(如果node有多个,则对应多条node的启动命令)
#hub节点上运行 java -jar selenium-server-.jar hub #node节点(非本机) java -jar selenium-server-.jar node --hub 192.168.10.157 #一定要指定hub的信息,不然会注册不上,官网没有这样说 #node节点(本机) java -jar selenium-server-.jar node -
但hub节点上也可以运行一个node节点,这个节点就无需指定--hub参数
-
当然上述的启动方式会默认检测浏览器驱动(搜索PATH路径下的driver.exe)和浏览器个数,配置都是自动的或默认的。
-
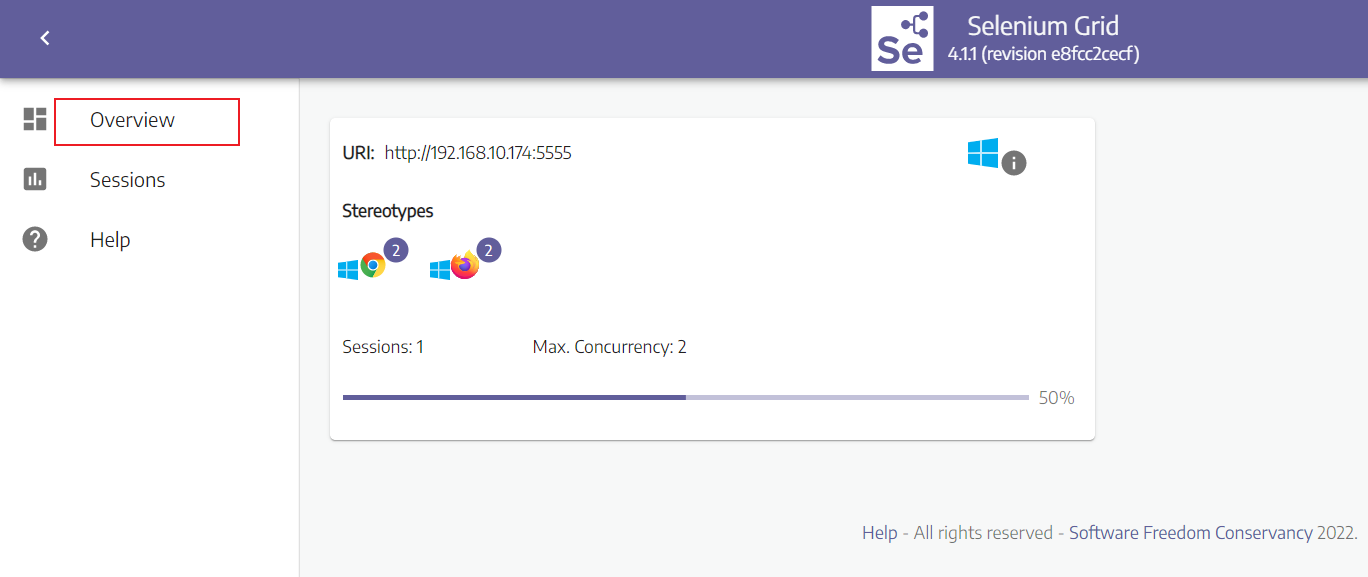
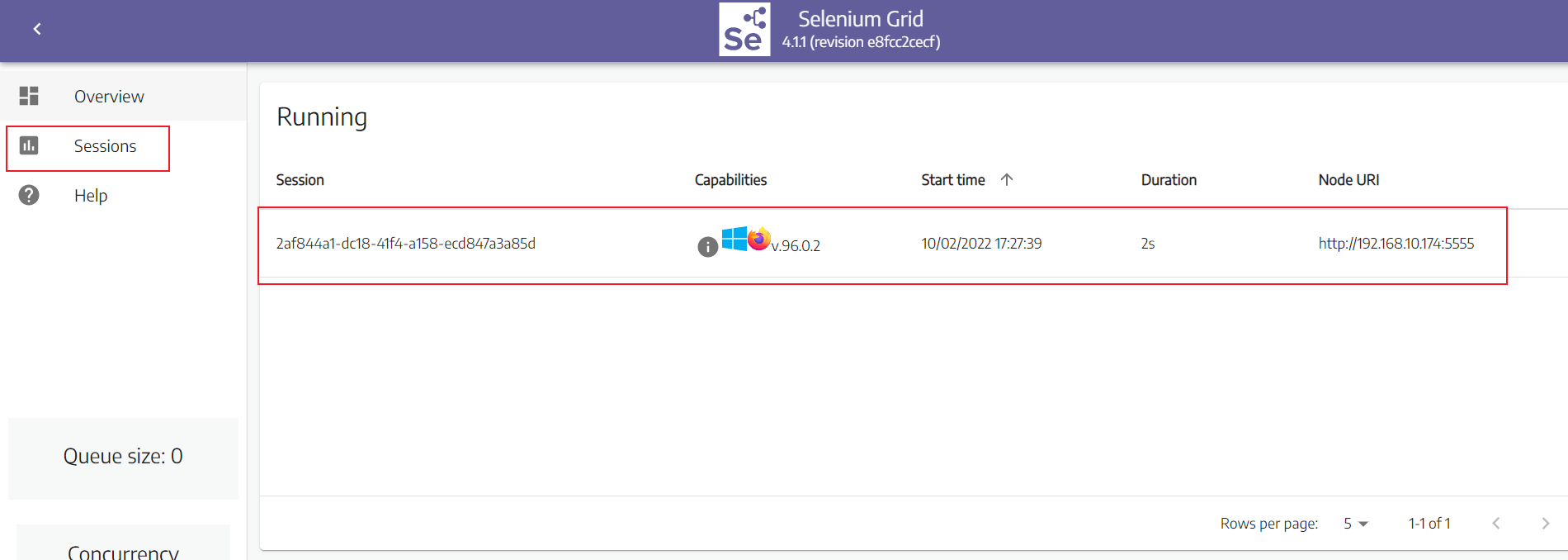
打开一个会话后的界面如下
-
Distributed 模式
-
最大型的Grid模式,完全分布式
-
你需要6-7条命令来启动每个组件
#1 启动event-busjava -jar D:\selenium_grid\selenium-server-4.1.1.jar event-bus#2 启动sessionsjava -jar D:\selenium_grid\selenium-server-4.1.1.jar sessions #默认是5556端口#3 启动sessionqueuejava -jar D:\selenium_grid\selenium-server-4.1.1.jar sessionqueue #默认是5559端口#4 启动distributorjava -jar D:\selenium_grid\selenium-server-4.1.1.jar distributor --sessions http://192.168.10.157:5556 --sessionqueue http://192.168.10.157:5559 --bind-bus false#5 启动routerjava -jar D:\selenium_grid\selenium-server-4.1.1.jar router --sessions http://192.168.10.157:5556 --sessionqueue http://192.168.10.157:5559 --distributor http://192.168.10.157:5553 #默认是5553端口#6. 启动本机node## 本机节点无需指定hubjava -jar D:\selenium_grid\selenium-server-4.1.1.jar node #自动注册到本机java -jar D:\selenium_grid\selenium-server-4.1.1.jar node --detect-drivers true #检测驱动java -jar D:\selenium_grid\selenium-server-4.1.1.jar node --driver-implementation "firefox" --max-sessions 5 #配置指定的浏览器和多少个实例2000 #7 启动外机node,需要指定hub地址java -jar selenium-server-4.1.1.jar node --hub 192.168.10.157 --driver-implementation "firefox" --max-sessions 5java -jar selenium-server-4.1.1.jar node --hub 192.168.10.157 --driver-implementation "chrome" --max-sessions 5 -
启动节点的时候可以用配置文件的方式来读取,这里推荐用toml格式
#node节点使用的toml [node] driver-implementation = ["chrome"] #官网此处是错的,用的是driver max-sessions = 3
命令帮助
-
参考
java -jar selenium-server-.jar hub --help java -jar selenium-server-.jar node --help
测试实例
-
分布式测试可以结合pytest-xdist插件,利用-n参数来同时执行多个用例
@pytest.mark.parametrize('browsertype',['chrome','firefox']) def test_grid(browsertype): from selenium import webdriver if browsertype =='chrome': options = webdriver.ChromeOptions() if browsertype == 'firefox': options = webdriver.FirefoxOptions() driver = webdriver.Remote(command_executor='http://127.0.0.1:4444', options=options) driver.get('https://www.baidu.com') from time import sleep sleep(5) driver.quit() if __name__ == '__main__': pytest.main(['-sv','-n 2',__file__])
Python 面向对象知识巩固
概念
-
面向对象,即OOP,Object Oriented Programming,是一种程序设计方法。
-
python中一切皆对象,通过type方法可以看到任何数据都是以class的形式存在的
>>> type(1) <class 'int'> -
面向对象最重要的概念就是类(Class)和实例(Instance),类是抽象的模板。实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。
-
- 比如人类是一个类,那你就是一个实例(具体的人)
- 比如学生是一个类,那你就是一个实例(具体的学生)
- 比如三角形是个类,那么边长分别为3-4-5的三角形就是一个实例(具体的三角形)
类定义
class 类名(父类列表):
数据和方法的定义
-
类名:一般建议是驼峰命名,首字母一般大写
-
示例
class Person(object): #python中所有类都继承自object #class Person(): #没有继承非object类的时候()可以写 #class Person: #也可以不写 pass
类的实例化
-
示例
class Person: pass zhangsan = Person() #实例化,()不能少 -
实际是在调用
__init__方法,没有这个方法就是什么都不做(不需要传递任何参数)。参见下文的类的魔术方法。
类变量
-
访问类的数据,用类名.变量名的
-
示例
class Person: head_num = 1 #这是一个类变量 print(Person.head_num) #可以直接输出1
-
python中没有像java中的private将类的数据和方法设置为私有,python是通过名字的变更(加双下划线)来实现的。
-
示例
class Person: __sex = 'unknow' print(Person.__sex) #AttributeError: type object 'Person' has no attribute '__sex' -
如果要访问,建议是增加个方法来访问该数据。但也可以通过下面这种方式来访问
print(Person._Person__sex)
-
类属性可以自由添加
-
属性更改:python是一门动态语言,类的属性可以自行添加(也有人觉得不好,那python也提供了方式来控制)
class Person: head_num = 1 zhangsan = Person() zhangsan.head_num=2 #更改属性值 print(zhangsan.head_num) zhangsan.sex = 'male' #添加属性值 print(zhangsan.sex) -
可以通过setattr内建方法来批量设置属性
attr_value = { 'color':'yellow', 'height':'178cm', 'weight':'75kg', } for attr,value in attr_value.items(): setattr(zhangsan,attr,value) print(zhangsan.color) #yellow print(zhangsan.weight) #75kg
类的方法
- 类中的函数称为方法,方法有很多种
- 类方法的命名一般是小写的单词组合,可以用下划线连接
- 调用类方法的方式,就是**类名.方法名(参数)**的方式
类的实例方法
-
类的方法的第一个参数是self,这是个约定,可以不写self,但不推荐,
-
示例
class Person: def say_hi(self): print('Hi')zhangsan = Person()zhangsan.say_hi() #输出Hi< 2000 /pre>
类的魔术方法
-
双下划线开头的方法都是私有方法
-
前后都是双下划线的方法是特殊的,称之为魔术方法,比如构造方法__init__
class Person: def __init__(self,sex): #形参 sex self.xingbie = sex #初始化的时候,sex具体的值赋值给实例的xingbie变量 zhangsan = Person('男') #传入一个参数sex,self是不要传入的 #实例化的时候自动去调用__init__方法,将sex这个参数的值'男'传递给张三这个实例的xingbie变量 james = Person('male') #实例化的时候自动去调用__init__方法,将sex这个参数的值'male'传递给james这个实例的xingbie变量 print(zhangsan.xingbie) #输出 男 print(james.xingbie) #输出 male
-
本质上实例化的过程是这样的
class Person: def __init__(self,sex): &nb 1000 sp; self.xingbie = sexlisi = object.__new__(Person)Person.__init__(lisi,'女')print(lisi.xingbie) -
常见的魔术方法和特殊属性
魔术方法 说明 init() 构造方法 del() 析构方法 call() 实例()会执行的方法 len() len(实例)的时候做的事情,等价于实例._len() add() 重载加法,类似的还有__sub__()、div()、mul()、mod()、pow() iter() 迭代器方法,该类可以用for循环遍历需要实现的方法 getitem() 该类可以用[]来取索引需要实现的方法,类似的还有setitem和delitem 特殊属性 说明 doc 说明文档(函数也有该属性) file 文档所在的绝对路径 module 当前操作的对象所在的模块 class 当前操作的对象所在的类 dict 列出类或对象中的所有成员 author 作者信息
静态方法 @staticmethod
-
静态方法绑定到一个类而不是该类的对象。
-
当我们需要某些功能而不是对象,而需要完整的类时,我们可以使方法静态化。
-
在静态方法中,我们不需要将
self作为第一个参数传递 -
静态方法的实现方法之一:不推荐
class Person: def sayhi(): print('Hi') Person.sayhi = staticmethod(Person.sayhi) Person.sayhi() #Hi zhangsan= Person() zhangsan.sayhi() #Hi,可以通过实例来调用,但并不推荐 -
静态方法的实现方法之二:推荐方法
class Person: @staticmethod def sayhi(): print('Hi') Person.sayhi() #Hi zhangsan = Person() zhangsan.sayhi() #Hi,可以通过实例来调用,但并不推荐
类方法 @classmethod
-
类方法是用类本身调用的方法(实例也能调用)。 这些方法通常定义对象的行为并修改对象的属性或实例变量。
-
示例
class Person: @classmethod def run(cls): print('run run run ',cls) Person.run() #run run run
| 实例方法 | 静态方法 | 类方法 | |
|---|---|---|---|
| 定义 | @staticmethod装饰 | @classmethod装饰 | |
| 参数 | 第一个参数self | 参数无要求 | 第一个参数cls |
| 调用 | 实例调用 | 类调用,不推荐实例调用(但可) | 类调用,不推荐实例调用(但可) |
| 是否常用 | Y | N | N |
| 应用场景 | 传递实例的属性和方法;也可以传递类的属性和方法 | 不能使用类或实例的任何属性和方法 | 传递类的属性和方法(不能传实例的属性和方法) |
类方法的一个例子
-
需求:有个班级类,有个学生类,学生类继承自班级类,要求每当有一个学生实例化的时候,班级类中学生总数就加1
-
参考代码
class MyClass: __student_num = 0 @classmethod def add_student(cls): cls.__student_num+=1 @classmethod def get_studentnum(cls): return cls.__student_num def __new__(cls, *args, **kwargs): MyClass.add_student() return super().__new__(cls) class Student(MyClass): pass a1 = Student() a2 = Student() a3 = Student() print(MyClass.get_studentnum())
继承和多态
-
类是抽象的模板,那模板很多的时候就是用来套用的,这就是继承。
-
继承的好处在于公共的部分放在基类(父类、超类)中,子类关心自己的实现即可,子类拥有父类的一切;如果子类实现了父类的方法,那么优先采用自己的方法(这是多态)
-
示例
class Person: def __init__(self,name,sex): self.mingzi = name self.xingbie = sex def eat(self): print('i cat eat') def introduce(self): print(f'my name is {self.mingzi},i am {self.xingbie}') class Chinese(Person): #中国人是人类,继承了人类的属性和方法 def introduce(self): #重写introduce方法,多态 print(f'我叫{self.mingzi},我是{self.xingbie}的') kobe = Person('kobe','male') kobe.introduce() #my name is kobe,i am male zhangsan = Chinese('张三','男') zhangsan.introduce() #我叫张三,我是男的 zhangsan.eat() #i cat eat;子类可以用超类的方法 print(isinstance(kobe, Person)) #True print(isinstance(zhangsan, Chinese)) #True,子类是Chinese,但也是Person print(isinstance(zhangsan, Person)) #True
多重继承
-
子类可以继承多个父类,子类在调用某个方法或属性的时候,首先在自身寻找,如果没有就找第一个父类,如果没有就找第二个父类
-
如果父类还有父类,那遵循深度优先的原则
-
示例
class A_1(): pass # def test(self): # print('A1 testing') class A_2(A_1): pass # def test(self): # print('A2 testing') class B_1(): # pass def test(self): print('B1 testing') class B_2(B_1): pass # def test(self): # print('B2 testing') class C(A_2,B_2): pass # def test(self): # print('C testing') c = C() c.test() #你需要逐一注释那些类的方法定义 #如第一次,反注释C自己的test方法,会发现调用的是C自己的test方法 #第二次,反注释A2的test方法,注释C的test方法,你会发现调用A2的test方法 #第三次,注释C和A2的test方法,再反注释A1的test方法,你会发现调用A1的test方法 #第四次,注释C/A1/A2的test方法,反注释B2的test方法,你会发现调用B2的test方法 -
综上,继承的调用顺序是类似于这样的(继承顺序从左到右,深度优先)
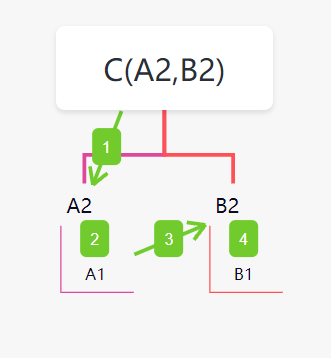
单例模式
23 种设计模式可以分为三大类:创建型模式、行为型模式、结构型模式。单例模式属于创建型模式的一种,单例模式是最简单的设计模式之一:单例模式只涉及一个类,确保在系统中一个类只有一个实例,并提供一个全局访问入口。许多时候整个系统只需要拥有一个全局对象,这样有利于我们协调系统整体的行为。
很多初学者喜欢用全局变量,因为这比函数的参数传来传去更容易让人理解。确实在很多场景下用全局变量很方便。不过如果代码规模增大,并且有多个文件的时候,全局变量就会变得比较混乱。你可能不知道在哪个文件中定义了相同类型甚至重名的全局变量,也不知道这个变量在程序的某个地方被做了怎样的操作。
介绍
- 单例是一种设计模式,应用该模式的类只会生成一个实例。
- 单例模式的作用是:让类创建的对象,在内存中只有唯一的实例(内存地址一样)
应用场景
1、 日志类
日志类通常作为单例实现,并在所有应用程序组件中提供全局日志访问点,而无需在每次执行日志操作时创建对象。
2、 配置类
将配置类设计为单例实现,比如在某个服务器程序中,该服务器的配置信息存放在一个文件中,这些配置数据由一个单例对象统一读取,然后服务进程中的其他对象再通过这个单例对象获取这些配置信息,这种方式简化了在复杂环境下的配置管理。
3、工厂类
假设我们设计了一个带有工厂的应用程序,以在多线程环境中生成带有 ID 的新对象(Acount、Customer、Site、Address 对象)。如果工厂在 2 个不同的线程中被实例化两次,那么 2 个不同的对象可能有 2 个重叠的 id。如果我们将工厂实现为单例,我们就可以避免这个问题,结合抽象工厂或工厂方法和单例设计模式是一种常见的做法。
4、以共享模式访问资源的类
比如网站的计数器,一般也是采用单例模式实现,如果你存在多个计数器,每一个用户的访问都刷新计数器的值,这样的话你的实计数的值是难以同步的。但是如果采用单例模式实现就不会存在这样的问题,而且还可以避免线程安全问题。
5、在Spring中创建的Bean实例默认都是单例模式存在的。
6、其他情况
还比如系统中可以存在多个打印任务,但同一时刻就一个正在运行的;一个音乐播放器可以播放很多音乐,但一次就播放一个音乐。游戏中需要有“场景管理器”这样一种东西,用来管理游戏场景的切换、资源载入、网络连接等等任务。这个管理器需要有多种方法和属性,在代码中很多地方会被调用,且被调用的必须是同一个管理器,否则既容易产生冲突,也会浪费资源。这种情况下,单例模式就是一个很好的实现方法。
原理说明
-
python的__new__方法
-
- object基类提供的内置静态方法
- 在内存中为对象分配空间
- 返回对象引用
- Python解释器获得对象引用后,将引用作为第一个出参传递给__init__方法(所以new在init之前)
-
关于__new__和__init__的一些区别
-
- __init__通常用于初始化一个新实例,控制这个初始化的过程,比如添加一些属性, 做一些额外的操作,发生在类实例被创建完以后。它是实例级别的方法。
- __new__通常用于控制生成一个新实例的过程。它是类级别的方法。
- __new__至少要有一个参数cls,代表要实例化的类,此参数在实例化时由Python解释器自动提供
- __new__必须要有返回值,返回实例化出来的实例,这点在自己实现new时要特别注意,可以return父类new出来的实例,或者直接是object的new出来的实例
- 可以将类比作制造商,new方法就是前期的原材料购买环节,init方法就是在有原材料的基础上,加工,初始化商品环节
单例的优缺点
优点:
- 单例对象在内存中只有一个,节省内存空间;
- 可以避免频繁的创建销毁对象,减轻 垃圾回收 工作,进而可以提高性能;
- 避免对共享资源的多重占用,简化访问;
- 为整个系统提供一个全局访问点。
缺点:
- 不适用于变化频繁的对象;
- 滥用单例将带来一些负面问题,如为了节省资源将数据库连接池对象设计为的单例类,可能会导致共享连接池对象的程序过多而出现连接池溢出;
- 如果实例化的对象长时间不被利用,系统会认为该对象是垃圾而被回收,这可能会导致对象状态的丢失;
单例模式的实现
new关键字
class A:
__instance = None #类变量 它用来存放实例,如果 _instance 为 None,则新建实例,否则直接返回 _instance 存放的实例。
__flag = True #类变量
def __new__(cls, *args, **kwargs): #固定的部分
if cls.__instance is None: #如果类从来没被调用过,那么就是None(最初的样子)
cls.__instance = object.__new__(cls) #如果调用过,就不是None了
#cls.__instance = super().__new__(cls) #也可以这么写
#cls.__instance = object.__new__(cls, *args, **kwargs)
return cls.__instance #new方法必须要返回一个实例
def __init__(self): #如果只做上面的,那么init方法仍然会多次调用 , 如果你希望值做一次init,同理可以这么玩。
if A.__flag:
print('haha')
A.__flag =False
a = A()
aa = A()
print(a)
print(aa)
print(a._A__flag)
print(a._A__instance)
----输出
haha
<__main__.A object at 0x0000025117E7F988>
<__main__.A object at 0x0000025117E7F988>
False
<__main__.A object at 0x0000025117E7F988>
-
在这里要注意一点
class Singleton1(object): def __new__(cls, *args, **kwargs): if not hasattr(cls,'_instance'): cls._instance = super().__new__(cls) return cls._instance class Singleton1(object): def __new__(cls, *args, **kwargs): if not hasattr(cls,'__instance'): #双下划线不行,单的可以,因为__是私有变量无法访问 cls.__instance = super().__new__(cls) return cls.__instance
单例模式的其他实现方式 :装饰器实现
def singleton(cls):
_instance = {}
#★使用不可变的类地址作为键,其实例作为值,每次创造实例时,首先查看该类是否存在实例,存在的话直接返回该实例即可,否则新建一个实例并存放在字典中。
def inner():
if cls not in _instance:
_instance[cls] = cls()
return _instance[cls]
return inner
@singleton
class Cls(object):
def __init__(self):
pass
cls1 = Cls()
cls2 = Cls()
print(id(cls1) == id(cls2))
单例模式的其他实现:类装饰器
class Singleton(object):
def __init__(self, cls):
self._cls = cls
self._instance = {}
def __call__(self):
if self._cls not in self._instance:
self._instance[self._cls] = self._cls()
return self._instance[self._cls]
@Singleton
class Cls2(object):
def __init__(self):
pass
cls1 = Cls2()
cls2 = Cls2()
print(id(cls1) == id(cls2))
-
由于是类,还可以这么用
class Cls3(): pass Cls3 = Singleton(Cls3) cls3 = Cls3() cls4 = Cls3() print(id(cls3) == id(cls4))
单例模式的其他实现:metaclass
-
了解在 Python 中一个类和一个实例是通过哪些方法以怎样的顺序被创造的。
-
简单来说,元类(metaclass) 可以通过方法 metaclass 创造了类(class),而类(class)通过方法 new 创造了实例(instance)。
在单例模式应用中,在创造类的过程中或者创造实例的过程中稍加控制达到最后产生的实例都是一个对象的目的。
-
同样,我们在类的创建时进行干预,从而达到实现单例的目的。
def func(self): print("do sth") Klass = type("Klass", (), {"func": func}) c = Klass() c.func() #用type创造了一个类#这里,我们将 metaclass 指向 Singleton 类,让 Singleton 中的 type 来创造新的 Cls4 实例。 class Singleton(type): _instances = {} def __call__(cls, *args, **kwargs): if cls not in cls._instances: cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs) return cls._instances[cls] class Cls4(metaclass=Singleton): pass cls1 = Cls4() cls2 = Cls4() print(id(cls1) == id(cls2))
---
pytest介绍
- 简单灵活,容易上手,文档丰富;
- 支持参数化,可以更细力度地控制需要测试的测试用例
- 能够支持简单的单元测试和复杂的功能测试,还可以用来做selenium/appnium等自动化测试,接口自动化测试(pytest+requests);
- pytest具有很多第三方插件,并且可以自定义扩展,比较好用的如pytest-selenium(集成selenium),pytest-html(测试报告生成),pytest-rerunfailures(失败case重复执行),pytest-xdist(多cpu分发)等;
- 测试用例的skip和xfail处理
- 可以很好的和CI工具结合,例如Jenkins
pytest基础
基于 Python 3.7.5, pytest-6.2.5测试
-
命名规范
-
-
测试类test开头也不行的
-
带init的话会有报错
cannot collect test class 'Test02' because it has a __init__ constructor -
比如testa、test01或者atest都是不行的
-
测试文件以test_开头(以_test结尾也可以) #这些原则是可以打破的,可以通过配置文件更改
-
测试类以Test开头,并且不能带有__init__方法
-
测试函数必须以test开头(不需要是test_)
-
断言使用基本的assert即可
-
所有的package必须有__init__.py文件
-
-
查找测试的策略:默认会递归寻找当前目录下的所有(符合命名规范的)测试脚本
-
控制台(console)实用参数
-
控制台(console)实用参数
参数 说明 示例 --collect-only 显示哪些用例被选到 -s 显示程序中的 print/logging 输出 -v 丰富信息模式, 输出更详细的用例执行信息 -k keyword,运行包含某个字符串的测试用例。如: pytest -k add XX.py 表示运行 XX.py 中包含 add 的测试用例。 -x 出现一条测试用例失败就退出测试。在调试阶段非常有用,当测试用例失败时,应该先调试通过,而不是继续执行测试用例。 -m mark,运行带有标记的测试用例 pytest -m 'm1';pytest -m 'm1 and m2' -h 查看帮助 -q 只显示整体的测试结果,相当于静默输出 --markers 显示所有pytest支持的markers 不是测试文件中的mark --setup-show 回溯fixture的执行过程 --fixtures 列出所有可供测试使用的fixture,包括重命名的
fixture及conftest
-
基本概念
-
-
函数不能以test开头,要和测试用例有区别
-
类似于setup和teardown,但更加灵活
-
fixture是测试函数运行前后,由pytest执行的外壳函数。常用于配置测试前系统的初始状态、为批量测试提供数据源、传入测试中的测试集
-
装饰器@pytest.fixture()声明一个函数是一个fixture。那么如果测试函数的参数列表中含有这个fixture的名字,pytest会在测试函数运行前执行该fixture(自动扫描)。所以fixture的命名、参数的命名都非常重要。
-
fixture可以放在一个测试文件中,也可以放在一个叫conftest.py的文件中供多个文件共享。
-
conftest.py的作用域是当前目录及子目录,conftest.py可以存在多个(肯定不是同一个目录下)
-
conftest.py是特殊的模块,无法import。conftest.py被pytest视为本地插件库,可以把conftest看做是一个供当前目录下所有测试文件使用的fixture仓库。
-
如果fixture函数包含yield,那么系统会在yield处停止,转去运行测试,等测试函数运行完毕再回到fixture执行yield后面的内容。在这里把yield前的内容视为setup,把yield后的视为teardown。但是无论测试过程中发生了什么yield之后的内容都会执行的。
-
可以用--setup-show回溯setup的运行过程!
-
fixture中可以返回数据给测试函数,可以是return(那就没有teardown,你写会语法错误,return不能同级还有语句),一般都用yield。返回的数据也可以是任意类型,多种数据。
-
fixture的scope
scope 含义 scope='session' 每个会话执行一次 scope='module' 每个模块运行一次 scope='class' 每个类执行一次 scope='function' 每个函数运行一次,默认值
-
-
除了在函数的参数列表中使用fixture,或者用autouse来自动使用fixture,也可以用@pytest.mark.usefixtures('f1','f2')来标记测试函数或测试类,使用usefixtures的时候需要在参数列表中指定fixture的名字,一般我们不用在测试函数中(但可以用),但非常适合用于测试类。
-
fixture的2种调用方法的区别在于,用参数的方法能使用fixture的返回值,用usefixtures可不行。
七:PO概念、浏览器封装

第一部分:PO概念
-
一个没有PO实现的测试用例
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from time import sleep import pytest class TestPolly: pollyurl = 'http://120.55.190.222:38090/#/login' username = ('id','username') def test_login_001(self): driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(20) driver.get(self.pollyurl) driver.find_element(*self.username).send_keys('松勤老师') driver.find_element_by_id('password').send_keys('123456') driver.find_element_by_id('btnLogin').click() assert driver.find_element_by_css_selector(".no-redirect").text =='首页' def test_add_product_001(self): driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(20) driver.get(self.pollyurl) driver.find_element(*self.username).send_keys('松勤老师') driver.find_element_by_id('password').send_keys('123456') driver.find_element_by_id('btnLogin').click() driver.find_element_by_xpath("//span[contains(text(),'商品管理')]").click() sleep(2) driver.find_element_by_css_selector("a[href='#/pms/addProduct'] span").click() mywait = WebDriverWait(driver,5,0.5) ele_product = mywait.until(EC.presence_of_element_located((By.XPATH,"//span[text()='添加商品']"))) assert ele_product.is_enabled() if __name__ == '__main__': pytest.main(['-sv',__file__]) -
上述代码的问题:
-
- 重用性低:登录功能重复
- 可维护性差:数据和代码混合
- 可读性差:元素定位方法杂乱(id、xpath、css混杂)
- 可读性差:不易识别操作的含义(特别是css和xpath语法)
- 可维护性差:如果某个元素的属性改了,你要更改多次
-
PO模型
-
- Page Object Model 页面对象模型
- PO是自动化测试项目开发实践的最佳设计模式之一
-
设计准则
-
- 相同的操作(但可能是不同的数据)带来的不同的结果可以封装成不同的方法。
-
-
The pulic methods represent the services that the page offers
-
- 使用公共方法来代表页面提供的服务
- 基类(基础服务:页面的基础的服务:点击元素,输入内容)
- 页面类:登录、添加商品
-
Try not to expose the internals of the page
-
- 不要暴露页面的内部细节(比如元素 ,元素的定位方法等),隔离了测试用例和业务和页面对象
-
Generally don't make assertions
-
- PO本身通常(绝)不应进行判断或断言. 判断和断言是� 1000 �试的一部分, 应始终在测试的代码内, 而不是在PO中. PO用来包含页面的表示形式, 以及页面通过方法提供的服务, 但是与PO无关的测试代码不应包含在其中
-
Methods return other PageObjects
-
-
方法返回其他的页面对象,进行页面的关联
-
- 登录->首页,首页->添加商品,推荐正向返回
- 添加商品,登出->登录页,不推荐反向返回
-
-
Need not represent an entire page
-
-
PO不一定需要代表整个页面,定义你所需要实现的业务的部分即可,所以在我们的测试中有的页面对象可以非常简单(用什么写什么). PO设计模式可用于表示页面上的组件. 如果自动化测试中的页面包含多个组件, 则每个组件都有单独的页面对象, 则可以提高可维护性.
-
-
Different results for the same action are modelled as different methods
-
- 相同的操作(但可能是不同的数据)带来的不同的结果可以封装成不同的方法。
-
补充
1. 实例化PO时, 应进行一次验证, 即验证页面以及页面上可能的关键元素是否已正确加载. 在上面的示例中, SignInPage和HomePage的构造函数均检查预期的页面是否可用并准备接受测试请求(selenium官网提到的) 2. 上述只是一个经验总结,非强制
-
-
分层模型:
-
- 表现层:页面中可见的元素,都属于表现层。(元素定位器的编写)
- 操作层:对页面可见元素的操作。点击、输入文本、获取文本等。(基类)
- 业务层:上面2层的组合,并联合到一起形成某个业务动作,在页面中对若干元素操作后所实现的功能。(页面类的方法,也可以是多个页面的组合)
- 测试用例就是组合了1个或多个页面的方法,操作对应的元素,完成的测试。测试用例本身不在PO内
-
换句话来说
-
- XX页面中的XX元素
- XX模块下的XX页面
- XX页面的XX元素的动作1+..动作2+..动作3形成的业务
-
非PO结构和PO结构对比
-
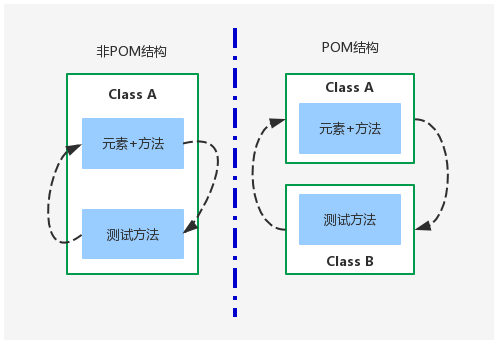
-
PO架构图
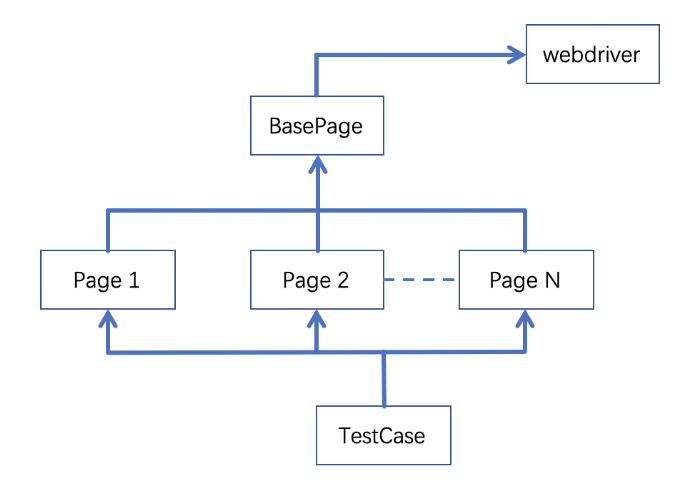
第二部分:项目结构
- selenium的实战是逐步展示这个结构的(需要什么建什么,让大家去理解为何要这么维护项目结构)
- 实战的时候就直接套这个目录结构了。
第三部分:浏览器封装
-
获取浏览器方法get_driver()
-
通过参数控制浏览器的默认类型(兼容性测试)
-
通过参数控制浏览器的模式,可以无头运行
-
通过参数控制隐式等待时间
-
优化:单例实现(参数化登录用例发现打开多个页面后改进)
-
示例代码
from selenium import webdriverfrom configs.env import Envclass Single(object): ''' 单例是一种设计模式 1. 直接用 2. 要去理解__new__ __init__ type 3. 单例的应用场景: log、自动化测试的时候浏览器、配置器、播放器 ''' _instance = None #实例 def __new__(cls, *args, **kwargs): if cls._instance is None: #此处是可以用__instance cls._instance = super().__new__(cls) return cls._instanceclass Single1(object): def __new__(cls, *args 2000 , **kwargs): if not hasattr(cls,'_instance'): #__instance 私有的 cls._instance = super().__new__(cls) return cls._instanceclass Comm_Driver(Single): """ 功能:打开一个浏览器 1. 测试多种浏览器 2. 配置参数:浏览器类型,是否有头,隐式等待时间 """ driver = None def get_driver(self, browser_type=Env.BROWSER_TYPE, headless_flag=Env.HEADLESS_FLAG): """ :param browser_type: 浏览器类型,取配置文件中的值作为默认值 :param headless_flag: 是否有头,取配置文件中的值作为默认值 :return: 返回一个浏览器对象 """ if self.driver is None: #如果没有打开过浏览器,就去打开... if not headless_flag: #如果有头模式 if browser_type == 'chrome': self.driver = webdriver.Chrome() elif browser_type == 'firefox': self.driver = webdriver.Firefox() &n 2000 bsp; # TODO 其他的浏览器测试你也可以加在此处 else: raise Exception(f'暂不支持当前的{browser_type}') else: if browser_type == 'chrome': _option = webdriver.ChromeOptions() #_option前面_是建议私有 _option.add_argument('--headless') #添加一个--headless参数 self.driver = webdriver.Chrome(options=_option) elif browser_type == 'firefox': _option = webdriver.FirefoxOptions() _option.add_argument('--headless') self.driver = webdriver.Firefox(options=_option) else: raise Exception(f'暂不支持当前的{browser_type}') self.driver.maximize_window() #最大化 self.driver.implicitly_wait(Env.IMPLICITLY_WAIT_TIME) #隐式等待 return self.driver #如果打开过了,就直接返回
八:基类封装和登录测试:PO实战
浏览器封装
-
功能
-
- 打开浏览器
- 通过参数控制浏览器类型
- 通过参数控制有头模式还是无头模式
- 通过参数控制隐式等待时间
-
示例代码
class CommDriver(Singe): """ 1. 通用的浏览器类 """ driver = None #设置一个类属性 def get_driver(self, browname=def_browname, headless=headless_flag, implicitly_wait_time=def_impwait_time): """ 1. 获取浏览器对象 :param browname: 浏览器名字,目前支持 :param headless: 是否有头,True是无头,False是有头 :param implicitly_wait_time: 隐式等待时间 :return: 返回一个浏览器 """ if self.driver is None: #如果获取过浏览器了,这个就有值了不会再做下面的事情 if not headless: if browname == 'chrome': self.driver = webdriver.Chrome() elif browname == 'firefox': self.driver = webdriver.Firefox() else: raise Exception(f'{browname} is not supported') else: if browname == 'chrome': self.__option = webdriver.ChromeOptions() self.__option.add_argument('-headless') self.driver = webdriver.Chrome(options=self.__option) elif browname == 'firefox': self.__option = webdriver.FirefoxOptions() self.__option.add_argument('-headless') self.driver = webdriver.Firefox(options=self.__option) else: raise Exception(f'{browname} is not supported') self.driver.maximize_window() self.driver.implicitly_wait(implicitly_wait_time) return self.driver -
单例优化
基类封装
-
功能
-
- 要注意,默认是追加输入,大部分是清空后输入所以要更改方法
- 打开浏览器
- 输入网址
- 定位元素
- 输入文本
- 点击元素
- 优化:等待后点击(触发:登录后要退出)
- 优化:等待后获取元素(触发:错误提示出现太快获取不到)
-
示例代码
class BasePage(): """ 基类 1. 打开浏览器 2. 输入网址 3. 定位元素 4. 输入文本 5. 点击元素 # 待补充 6. 等待后点击 7. 等待后获取 """ def __init__(self): self.driver = CommDriver().get_driver() def open_url(self,url): #二次封装实现的方法,提供更多的可能 """ 打开网址 :param url: 待打开的网址 :return: None """ self.driver.get(url) def get_element(self,locator): """ 定位元素 :param locator: 定位器 如 (By.ID,'username') ['id','username'] :return: 返回元素 """ return self.driver.find_element(*locator) def input_text_old(self, locator, text): """ 在元素上输入内容 :param locator: 定位器 :param text: 输入的内容 :return: None """ warnings.warn('input_text_old is deprecated,please use input_text instead',DeprecationWarning) self.get_element(locator).send_keys(text) def input_text(self,locator,text,append=False): """ 清空原内容后再输入内容 保留原内容追加输入内容 :param locator: 定位器 :param text: 输入文本 :param append: True是追加输入,Flase是清空后输入 :return: None """ if not append: self.get_element(locator).clear() self.get_element(locator).send_keys(text) else: self.get_element(locator).send_keys(text) def click_element(self,locator): """ 点击元素 :param locator: 定位器 :return: None """ self.get_element(locator).click() #增加一个方法,获取元素的文本 def get_element_text(self,locator): 8000 """ 获取元素的文本 :param locator: 定位器 :return: """ return self.get_element(locator).text def wait_click_element(self,locator): # TODO 你可以封装这个函数,设置超时时间和轮询时间 WebDriverWait(self.driver,5,0.5).\ until(EC.visibility_of_element_located(locator)).click() def wait_get_element_text(self,locator): return WebDriverWait(self.driver,5,0.5).\ until(EC.visibility_of_element_located(locator)).text
登录页封装
-
功能
-
- 打开登录页
- 登录系统
-
示例代码
class LoginPage(BasePage): """ 登录页面 1. 打开登录页 2. 登录系统 """ def open_loginpage(self): self.open_url(POLLY_URL) def login_polly(self,username,password): #要用到页面元素 #元素的封装可以用py文件,也可以用其他类型的配置文件 self.input_text(username_input,username) self.input_text(password_input,password) self.click_element(login_button)
测试用例
-
简单的成功登录测试用例
def test_login_001(): """ 最简单的登录测试 :return: """ test_loginpage = LoginPage() test_loginpage.open_loginpage() test_loginpage.login_polly(USERNAME1,PASSWORD1) #断言: 测试思想的体现 #首页出现另一个首页元素 #判断这个首页元素的文本是“首页” assert test_loginpage.get_element_text(['xpath','//*[text()="首页"]']) == '首页' -
多组成功登录测试用例
@pytest.mark.parametrize('username,password', [('松勤老师','123456'), ('PW179038','123456')]) def test_login_success(username,password): """ 登录成功的测试: 正向用例 :return: """ test_loginpage = LoginPage() test_loginpage.open_loginpage() test_loginpage.login_polly(username,password) #断言: 测试思想的体现 #首页出现一个首页元素 #判断这个首页元素的文本是“首页” assert test_loginpage.get_element_text(['xpath','//*[text()="首页"]']) == '首页' #第一次登录后页面停住了,要退出后再登录 #点击个人中心按钮 test_loginpage.click_element(['xpath','//img']) #点击退出 test_loginpage.wait_click_element(['xpath',"//span[text()='退出']"]) -
多组失败登录用例
@pytest.mark.parametrize('username,password,locator,expected', get_yaml_data(f'{test_datas_path}login_failed_data.yaml')) def test_login_failed(username,password,locator,expected): """ 登录失败的用例 1. 用户名输入错误,密码正确 预期出现提示"用户名或密码错误" 2. 密码输入错误 预期出现提示"密码不正确" 3. 密码太短 预期出现提示"密码不能小于3位" 输入数据不同,判断的依据不同(元素不同,内容不同) username,password,(元素定位器),预期结果 YAML是非常契合这种数据的构造的 :return: """ test_loginpage = LoginPage() test_loginpage.open_loginpage() test_loginpage.login_polly(username,password) assert test_loginpage.wait_get_element_text(locator) == expected
yaml基础
-
yaml数据的读取
import yaml from pprint import pprint from utils.handle_path import test_datas_path def get_yaml_data(yaml_file): with open(yaml_file,encoding='utf-8') as f: return yaml.safe_load(f.read()) if __name__ == '__main__': pprint(get_yaml_data(f'{test_datas_path}login_failed_data.yaml'))
pytest基础
- 参数
| 参数 | 说明 | 示例 |
|---|---|---|
| --collect-only | 显示哪些用例被选到 | |
| -s | 显示程序中的 print/logging 输出 | |
| -v | 丰富信息模式, 输出更详细的用例执行信息 | |
| -k | keyword,运行包含某个字符串的测试用例。如: | pytest -k add XX.py 表示运行 XX.py 中包含 add 的测试用例。 |
| -x | 出现一条测试用例失败就退出测试。在调试阶段非常有用,当测试用例失败时,应该先调试通过,而不是继续执行测试用例。 | |
| -m | mark,运行带有标记的测试用例 | pytest -m 'm1' |
| -h | 查看帮助 | |
| -q | 只显示整体的测试结果,相当于静默输出 | |
| --markers | 显示所有pytest支持的markers | 不是测试文件中的mark |
os基础
- 通过__file__获取当前文件的绝对路径
- 通过os.path.dirname获取目录路径
- 通过os.path.join来拼接路径
- 通过
import os
project_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
common_path = os.path.join(project_path,'common\\')
test_datas_path = os.path.join(project_path,'test_datas\\')
if __name__ == '__main__':
print(test_datas_path)
plantuml画类图
-
在pycharm中下载插件PlantUML integration
-
右键某个工程下的目录,新建->PlanUML FILE
@startuml #开始 package common <<folder>> #包,标记为目录形式 { package comm_driver.py <<Frame>> #包,标记位框架形式(类似于内联框架) { class CommDriver #类的注释,和下面一行联合使用 note left:浏览器类 #注释在左侧 class CommDriver #类 声明 { +get_driver() #方法 } class Single note top:单例实现 class Single { } } CommDriver --> Single :继承 #指向 语法类1 --> 类2 :注释 ;-->还有其他用法 } @enduml #结束
九:商品管理测试 :basePage优化
截图和日志
-
截图
-
- 用selenium提供的save_screenshot即可
- 注意存放位置
- 文件命名可以用参数传递进来
-
日志
-
- 不要迷信日志,特别是你才写了一点点代码的时候
- 日志相对成熟,可以直接调用已有的
- 代码的调试可以借助print,debug,trace等手段
- python标准库的logging相对复杂(虽然也有简单的调用方式)
- loguru是一种新兴的日志方式
-
示例
def get_element(self,locator,desc=None): """ 定位元素 异常保护,如果定位不到就可以截图、日志 :param locator: 定位器 如 (By.ID,'username') ['id','username'] :return: 返回元素 """ try: return self.driver.find_element(*locator) except: current_time = strftime('%Y%m%d%H%M%S') self.driver.save_screenshot(f'{screenshots_path}{desc}定位不到{current_time}.png') #方式一 : 甚至可以用print,当你的代码比较小的时候 #logging.error(f'{desc}无法定位') #方式二 : 写到文件中 # log_time = strftime('%Y%m%d') #再控制下追加写入 # logging.basicConfig(filename=f'{logs_path}{current_time}.log') # logging.error(f'{desc}无法定位') #方式三:封装logging log.error(f'{desc}无法定位') -
扩展
-
- 截图也可以单独封装为一个方法,供各个基类方法调用捕获
logging
-
示例代码
print()"""日志相关内容: 1- 日志的输出渠道:文件xxx.log 控制台输出 2- 日志级别: DEBUG-INFO-WARNING-ERROR-CRITICAL 3- 日志的内容:2021-10-20 13:50:52,766 - INFO - handle_log.py[49]:我是日志信息 年- 月 - 日 时:分:秒,毫秒 -级别 -哪个文件[ 1000 哪行]:具体报错信息 https://www.liujiangblog.com/course/python/71"""from time import strftimeimport loggingfrom utils.handle_path import logs_path#这部分不存在单例def logger(fileLog=True,name=__name__): """ :param fileLog: bool值,如果为True则记录到文件中否则记录到控制台 :param name: 默认是模块名 :return: 返回一个日志对象 """ #0 定义一个日志文件的路径,在工程的logs目录下,AutoPolly开头-年月日时分.log logDir = f'{logs_path}/AutoPolly-{strftime("%Y%m%d%H%M")}.log' #1 创建一个日志收集器对象 logObject = logging.getL 2000 ogger(name) #2- 设置日志的级别 logObject.setLevel(logging.INFO) #3- 日志内容格式 fmt = "%(asctime)s - %(levelname)s - %(filename)s[%(lineno)d]:%(message)s" formater = logging.Formatter(fmt) if fileLog:#输出到文件 #设置日志渠道--文件输出 handle = logging.FileHandler(logDir,encoding='utf-8') #日志内容与渠道绑定 handle.setFormatter(formater) #把日志对象与渠道绑定 logObject.addHandler(handle) else: #输出到控制台 #设置日志渠道--控制台输出 handle2 = logging.StreamHandler() #日志内容与渠道绑定 handle2.setFormatter(formater) #把日志对象与渠道绑定 logObject.addHandler(handle2) return logObjectlog = logger()#文件输出日志if __name__ == '__main__': log = logger(fileLog=False)#控制台输出日志 log.info('我是日志信息')
loguru
-
示例代码
# Author: wuxianfeng# Company: songqin# File: handle_loguru.py# Date: 2021/10/24# Time: 9:30print()'''知识点:https://loguru.readthedocs.io/en/stable/overview.html#ready-to-use-out-of-the-box-without-boilerplate'''# Author: wuxianfeng# Company: songqin# File: handle_loguru.py# Date: 2021/9/26# Time: 21:26from configparser import ConfigParserfrom loguru import loggerfrom utils.handle_path import logs_path, config_pathfrom time import strftimeclass MyLog(): __instance = None #单例实现 __init_flag = True #控制init调用,如果调用过就不再调用 def __new__(cls, *args, **kwargs): if not cls.__instance: cls.__instance = super().__new__(cls) return cls.__instance def __init__(self): if self.__init_flag: #看是否调用过 __curdate = strftime('%Y%m%d-%H%M') cfg = ConfigParser() cfg.read(config_path+'loguru.ini',encoding='utf-8') logger.remove(handler_id=None) #关闭console输出 logger.add(logs_path+'AutoPolly_'+__curdate+'.log', #日志存放位置 retention=cfg.get('log','retention'), #清理 rotation=cfg.get('log','rotation'), #循环 达到指定大小后建立新的日志 format=cfg.get('log','format'), #日志输出格式 level=cfg.get('log','level')) #日志级别 self.__init_flag = False #如果调用过就置为False def info(self,msg): logger.info(msg) def warning(self,msg): logger.warning(msg) def critical(self,msg): logger.critical(msg) def error(self,msg): logger.error(msg) def debug 12000 (self,msg): logger.debug(self,msg)log = MyLog()if __name__ == '__main__': log1 = MyLog() log1.critical('test critical') from time import sleep sleep(1) log2 = MyLog() log2.error('test error') print(id(log1)) print(id(log2))
钩子函数
-
针对日志出现'\uXXXX'可以使用钩子函数pytest_collection_modifyitems,对用例的名字进行处理,这个钩子函数还可以对用例进行处理(比如调整顺序)
-
示例
def pytest_collection_modifyitems(items): """ 测试用例收集完成时,将收集到的item的name和nodeid的中文显示在控制台上 :return: """ for item in items: item.name = item.name.encode("utf-8").decode("unicode_escape") print(item.nodeid) item._nodeid = item.nodeid.encode("utf-8").decode("unicode_escape")
成功和失败用例的混合allure输出报告
-
注意事项
-
- 数据都封装在yaml中
- 混合后要注意成功后要退出,失败后无需退出,需要增加一个判断标记,推荐使用url来判断
- allure的基础
- pytest.assume插件
-
示例代码
@allure.severity('critical') #登录功能是其他模块的依赖,可以用插件pytest-dependency @pytest.mark.parametrize('casetitle,username,password,locator,expected', get_yaml_data(f'{test_datas_path}login_all_data.yaml')) @allure.title('{casetitle}') #此处不要写错 def test_login_all(self,casetitle,username,password,locator,expected): with allure.step('1. 打开登录页面'): test_loginpage = LoginPage() test_loginpage.open_loginpage() with allure.step('2. 登录宝利商城'): test_loginpage.login_polly(username,password) # assert test_loginpage.wait_get_element_text(locator) == expected # if test_loginpage.driver.current_url == MAINPAGE_URL: # # TODO 你可以去尝试用XX元素存在与否来控制下面的语句执行,你可能会遇到问题。可以用的! # test_loginpage.click_element(['xpath','//img']) #如果不控制直接点击该元素,就无法定位到 # test_loginpage.wait_click_element(['xpath',"//span[text()='退出']"]) # 如果断言失败了(界面跳转),也要去做下面的if控制流 # 可以用pytest的插件 pytest-assume with allure.step('3. 断言'): pytest.assume(test_loginpage.wait_get_element_text(locator) == expected) with allure.step('4. 断言后的处理'): if test_loginpage.driver.current_url == MAINPAGE_URL: # TODO 你可以去尝试用XX元素存在与否来控制下面的语句执行,你可能会遇到问题。可以用的! test_loginpage.click_element(['xpath','//img']) #如果不控制直接点击该元素,就无法定位到 test_loginpage.wait_click_element(['xpath',"//span[text()='退出']"])
allure基础
| 使用方法 | 参数值 | 参数说明 |
|---|---|---|
| @allure.epic() | epic描述 | 敏捷中的概念,定义为史诗,往下是feature |
| @allure.feature() | 模块名称 | 功能点的描述,往下是story |
| @allure.story() | 用户故事 | 往下是title |
| @allure.title('用例的标题') | 用例的标题 | html报告的名称 |
| @allure.testcase() | 测试用例的链接地址 | 对应功能测试用例系统中的具体用例 |
| @allure.issue() | 缺陷 | 对应缺陷管理系统中的链接 |
| @allure.description() | 测试用例描述 | |
| @allure.step() | 测试步骤 | |
| @allure.severity() | 用例等级 | blocker,critical,normal,minor,trivial |
| @allure.link() | 链接 | 定义一个链接,在测试报告中展现 |
| @allure.attachment() | 附件 | 报告添加附件 |
pytest.assume 断言后继续跑
-
安装
pip install pytest-assume -
实际测试的过程中,有可能遇到一种情况,就是你某个断言执行失败也想要做下去(比如登录的测试,测试失败后,还是要返回主页继续下一轮的测试)。而默认情况下,如果断言失败,assert后面的语句是不会执行的了。
-
可以应用在多重断言的场景!(可以同时做多个断言)
-
没有assume的示例
import pytest def test_001(): assert 1==2 #如果改为1==1,下面是不会执行的 print('\n对了会做,错了不会做') if __name__ == '__main__': pytest.main(['-s','test_order_001.py']) -
有assume的示例
import pytest def test_001(): pytest.assume(1==2) print('\n对了会做,错了也会做') if __name__ == '__main__': pytest.main(['-sv','test_order_001.py'])
测试用例:添加商品
-
第二个用例:我们先写用例再看要用到哪些页面(方法->元素)
-
用例步骤
1. 打开登录页 2. 登录宝利商城 3. 进入首页 : 新建一个首页的页面对象 4. 点击添加商品页面 : 新建一个添加商品的页面对象 5. 操作步骤 : 添加商品页面的方法 6. 断言: 切换到商品列表界面,判断第一个商品是否是刚才新增的商品 新建一个商品列表界面 商品列表界面:新增一个获取第一个商品名称的方法 操作步骤 #1. 点击商品分类 #2. 选择1级分类 #3. 选择2级分类 #4. 输入商品名称 #5. 输入副标题 #6. 点击商品品牌 #7. 选择1级分类 #8. 下一步,填写商品促销 #9. 下一步,填写商品属性 #10. 下一步,选择商品关联 #11. 完成,提交商品 #12. 确定
MainPage 首页
-
注意事项
-
- PO设计原则:Methods return other PageObjects
- 登录成功后出现首页
- 首页方法可以跳转到各个子菜单,返回页面对象的实例
- 页面元素定位器的获取优化
-
参考代码
class MainPage(BasePage): """ 首页 1. 跳转到各个子菜单(N多的方法) """ def goto_addproductpage(self): self.click_element(self.menu_productmanage) self.wait_click_element(self.submenu_pm_addproduct) return AddProductPage() def goto_productlistpage(self): self.click_element(self.menu_productmanage) self.wait_click_element(self.submenu_pm_productlist) return ProductListPage() -
loginPage的改造
def login_polly(self,username,password): #要用到页面元素 #元素的封装可以用py文件,也可以用其他类型的配置文件 self.input_text(self.username_input,username) self.input_text(self.password_input,password) self.click_element(self.login_button) return MainPage() #返回首页
页面定位器的优化
-
实现目标:
-
-
每个页面类拥有自己的页面元素(定向分发)
元素通过yaml封装成如下格式: 页面类: 元素名: 定位器 -
页面元素名是类的属性,值就是对应的定位器
setattr(obj,attr,value) #为一个对象设置属性
-
-
示例:basePage初始化方法
def __init__(self): self.driver = CommDriver().get_driver() #元素的获取在基类中实现,下面的方法一下获取所有的元素 #self.locators = get_yaml_data(f'{common_path}allelements.yaml') #最佳实践: 每个页面获取自己的元素 #每个页面: 类名区分页面 #应该在元素封装中定义不同的页面对应不同的元素-定位器 self.locators = get_yaml_data(f'{common_path}elements.yaml')[self.__class__.__name__] #优化 让具体的页面有这个属性(元素的名字) for element_name,locator in self.locators.items(): setattr(self,element_name,locator) #setattr设置 self实例 属性element_name的值是locator
AddProductPage 添加商品页面
-
示例代码:注意MD格式的缩进看的跟实际会有差异
class AddProductPage(BasePage): # 因为要切换回主页,所以要增加一个方法 def < 6e8f span style="box-sizing: border-box;color: rgb(0, 0, 255)">back_mainpage(self): self.click_element(self.home_button) def addproduct(self,kidx1,kidx2,pname,subtitle,bidx): # 1. 点击商品分类 self.click_element(self.product_kind_select) # 2. 选择1级分类 # # TODO 如果没有一分类? # 这个一级分类的元素定义是动态的 self.product_kind_select_index1[-1]=self.product_kind_select_index1[-1].format(kidx1) self.click_element(self.product_kind_select_index1) # 3. 选择2级分类 # TODO 如果没有二级分类? self.product_kind_select_index2[-1]=self.product_kind_select_index2[-1].format(kidx2) self.click_element(self.product_kind_select_index2) # 4. 输入商品名称 self.input_text(self.product_name,pname) # 5. 输入副标题 self.input_text(self.product_subtitle,subtitle) # 6. 点击商品品牌 self.click_element(self.product_brand_select) # 7. 选择1级分类 self.product_brand_select_idx[-1]=self.product_brand_select_idx[-1].format(bidx) self.click_element(self.product_brand_select_idx) # 8. 下一步,填写商品促销 self.click_element(self.next_commodity_promotion_btn) # 9. 下一步,填写商品属性 self.click_element(self.next_product_attribute_btn) # 10. 下一步,选择商品关联 self.click_element(self.netxt_product_related_btn) # 11. 完成,提交商品 self.click_element(self.complete_btn) # 12. 确定 self.click_element(self.submit_btn)
ProductListPage 商品列表页面
-
示例代码
class ProductListPage(BasePage): def get_firstproduct_name(self): return self.get_element_text(self.first_product)
测试方法 test_addproduct
-
注意页面的切换!!
-
示例代码
def test_addproduct(): """ 1. 打开登录页 2. 登录宝利商城 3. 进入首页 : 新建一个首页的页面对象 4. 点击添加商品页面 : 新建一个添加商品的页面对象 5. 操作步骤 : 添加商品页面的方法 6. 断言: 切换到商品列表界面,判断第一个商品是否是刚才新增的商品 新建一个商品列表界面 新增一个获取第一个商品名称的方法 :return: """ # test_loginpage = LoginPage() # test_loginpage.open_loginpage() # test_loginpage.login_polly('松勤老师','123456') # test_mainpage = MainPage() # test_mainpage.goto_addproductpage() #登录成功后切换到首页 test_mainpage = LoginPage().open_loginpage().login_polly('松勤老师','123456') test_addproductpage = test_mainpage.goto_addproductpage() # productname要做到不可重复,随机 test_pname = '自动化'+get_rand_str(5) title_name = '副标题'+get_rand_str(5) test_addproductpage.addproduct('1','1',test_pname,title_name,'1') # 添加完一个商品后还在添加商品页面 # 回到首页mainpage,再切换到productlist界面,获取第一个商品名字 test_addproductpage.back_mainpage() # 去到商品列表界面,要在test_mainpage上做,已经在首页 test_productlistpage = test_mainpage.goto_productlistpage() # 获取商品列表页面的第一个商品名字 result_productname = test_productlistpage.get_firstproduct_name() #断言 输入的商品名字跟当前页面中的商品名字一致 assert test_pname == result_productname if __name__ == '__main__': pytest.main(['-sv',__file__])
十:品牌搜索和知识点总结
测试用例:搜索品牌
-
用例步骤
1. 登录宝利商城 2. 点击品牌管理 : 新的页面 2.1 获取当前页的所有品牌 2.2 搜索指定的品牌信息 2.2.1 输入一个品牌 : 品牌来自于当前的页面(随机取一个) 2.2.2 点击查询结果 3. 断言:你搜索的品牌名 在查询结果中 -
品牌管理页及方法
from common.basePage import BasePageclass BrandManagePage(BasePage): def get_curpage_allbrands(self): #获取当前页所有品牌,此处设计基类的改造 return self.get_elements_text(self.all_brand_name_txt) def search_brand(self,brandname): #搜索指定品牌名 self.input_text(self.brand_search_input,brandname) self.wait_click_element(self.search_btn) #得到所 2000 有的品牌信息的,不推荐用点点点 #你可以借助于接口,如果有数据库的操作权限也可以调用数据库接口去获取 #如果你用点点点,你可能要加强制等待 #每个页面都有类似的locator,1页.locator=2页.locator #配合前端 增加一个搜索完毕的标志,非常好判断 -
基类改造:增加获取多个元素的文本的方法
def get_element_text(self,locator): """ 获取元素的文本 :param locator: 定位器 :return: """ return self.get_element(locator).text def get_elements_text(self,locator): #self.get_elements(locator)这是所有的元素 #遍历得到每个元素的text return [ele.text for ele in self.get_elements(locator)] -
mainpage改造:增加跳转到品牌管理的方法
def goto_brandmanagepage(self): self.click_element(self.menu_productmanage) self.wait_click_element(self.submenu_pm_brandmanage) return BrandManagePage() -
测试用例:示例代码
# Author: wuxianfeng # Company: songqin # File: test_searchbrand.py # Date: 2021/10/25 # Time: 20:34 from pageObjects.loginPage import LoginPage print() ''' 知识点:测试搜索品牌 ''' import pytest import random def test_searchbrand(init_pm): """ 1. 登录宝利商城 2. 点击品牌管理 : 新的页面 2.1 获取当前页的所有品牌 2.2 搜索指定的品牌信息 2.2.1 输入一个品牌 : 品牌来自于当前的页面(随机取一个) 2.2.2 点击查询结果 3. 断言:你搜索的品牌名 在查询结果中 :return: """ # 1. 登录宝利 test_mainpage = init_pm test_mainpage = LoginPage().open_loginpage().login_polly('松勤老师','123456') # 2. 跳转到品牌管理 test_brandpage = test_mainpage.goto_brandmanagepage() # 3. 获取当前页的所有品牌名 init_brands = test_brandpage.get_curpage_allbrands() print(init_brands) # 4. 随机取一个品牌 test_brandname = random.choice(init_brands) print(test_brandname) # 5. 搜索品牌 test_brandpage.search_brand(test_brandname) # 6. 搜索后的品牌信息 from time import sleep sleep(1) result_brands = test_brandpage.get_curpage_allbrands() print(result_brands) # 7. 断言 # 实现方法1 # 测试反向 result_brands.append('haha') # for _ in result_brands: # if test_brandname not in _: # assert False # else: # assert True # 实现方法2 # s = 'a' # result1 = ['a', 'ab', 'abc'] # True # result2 = ['a', 'ab', 'abc', 'b'] # False # print(list(filter(lambda x: s in x, result2))) assert len(list(filter(lambda x: test_brandname in x, result_brands)))==len(result_brands) # python的基础非常的重要 if __name__ == '__main__': pytest.main(['-sv',__file__]) -
上面的测试最后解决了一个小python问题
Question: 判断目标字符串S是否在结果字符串列表的每个元素中出现 s = 'a' result_true = ['a','aa','ab'] result_false = ['a','b']